
- (Обновлено:
- 8 минут


У цій статті ми розглянемо:
- Що таке robots.txt?
- Всі директиви файлу:
- Використання спецсимволів
- Як перевірити коректну роботу файлу
- Помилки, що часто допускаються
- Приклади robots.txt для різних CMS:
Що таке robots.txt?
Robots.txt – це текстовий файл, який містить у собі рекомендації для дій пошукових роботів. У цьому файл містяться інструкції (директиви), за допомогою яких можна обмежити доступ пошукових роботів до певних папок, сторінок і файлів, задати швидкість сканування сайту, вказати головне дзеркало або адресу карти сайту.
Обхід сайту пошуковими роботами починається з пошуку файлу роботс. Відсутність файлу не є критичною помилкою. У такому випадку роботи вважають, що обмежень для них немає і вони повністю можуть сканувати сайт.
Файл повинен бути розміщений у кореневому каталозі сайту та бути доступним за адресою https://mysite.com/robots.txt.
Інструкції стандарту виключення для роботів носять рекомендаційний характер, а не є прямими командами для роботів. Тобто існує ймовірність, що, навіть закривши сторінку в robots.txt, вона все одно потрапить у індекс.
Вказувати директиви у файлі потрібно тільки латиницею, використовувати кирилицю заборонено. Російські доменні імена можна перетворити за допомогою кодування Punycode.

Що потрібно закрити від індексації в robots.txt?
- сторінки з особистою інформацією користувачів;
- кошик і порівняння товарів;
- переписку користувачів;
- адміністративну частину сайту;
- скрипти.
Як створити robots.txt?
Скласти файл можна в будь-якому текстовому редакторі (блокнот, TextEdit та ін.). Можна створити файл robots.txt для сайту онлайн, скориставшись генератором файлу, наприклад, інструментом сервісу Seolib.
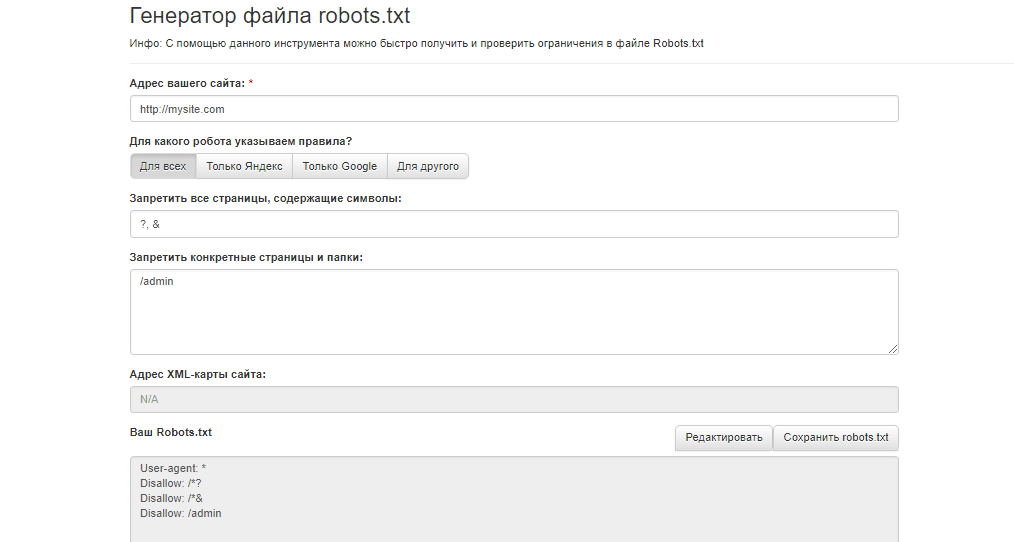
Чи потрібен robots.txt?
Прописавши правильні інструкції, боти не витрачатимуть краулінговий бюджет (кількість URL, які може обійти пошуковий робот за один обхід) на сканування непотрібних сторінок, а проіндексують тільки потрібні для пошуку сторінки. На додаток, не буде перевантажуватися робота серверу.
Директиви robots.txt
Файл роботс складається з основних директив: User-agent і Disallow і додаткових: Allow, Sitemap, Host, Crawl-delay, Clean-param. Нижче ми розберемо всі правила, для чого вони потрібні та як їх правильно прописати.
User-agent – вітання з роботом
Існує безліч роботів, які можуть сканувати сайт. Найбільш популярними є боти пошукових систем Google і Яндексу.
Роботи Google:
- Googlebot;
- Googlebot-Video;
- Googlebot-News;
- Googlebot-Image.
Роботи Яндексу:
- YandexBot;
- YandexDirect;
- YandexDirectDyn;
- YandexMedia;
- YandexImages;
- YaDirectFetcher;
- YandexBlogs;
- YandexNews;
- YandexPagechecker;
- YandexMetrika;
- YandexMarket;
- YandexCalendar.
У директиві User-agent вказують, до якого роботу звернені інструкції.
Для звернення до всіх роботів досить прописати наступний рядок у файлі:

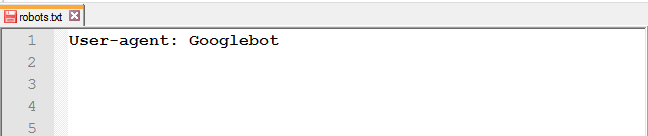
Для звернення до певної роботу, наприклад, до Google, потрібно прописати у цьому рядку його ім’я:
На відміну від Google, щоб не прописувати правила для кожного робота Яндексу, в User-agent можна вказати наступне:
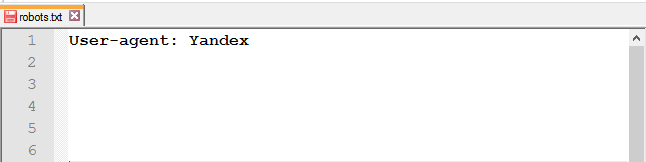
У Рунеті прийнято прописувати інструкції для двох User-agent: для всіх і окремо для Яндексу.
Директиви Disallow i Allow
Щоб заборонити роботу доступ до сайту, каталогу чи сторінки, використовуйте Disallow.
Як застосовувати правило Disallow у різних ситуаціях
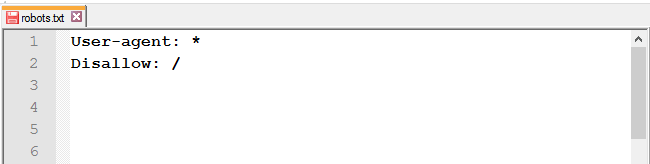
Закрити від індексації весь сайт: використовуйте слеш (/), щоб заблокувати доступ до всього сайту.
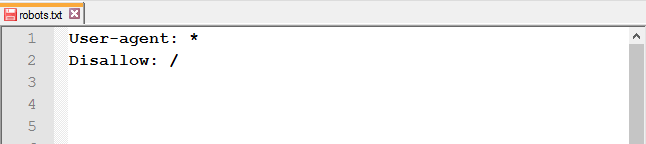
Повністю закривати доступ роботам варто на ранніх етапах роботи з сайтом, щоб у пошуковій видачі він з’явився вже готовим.
Закрити доступ до папки та її вмісту: використовуйте слеш після назви папки.
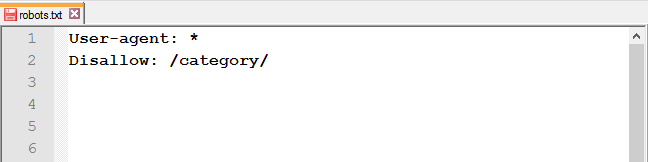
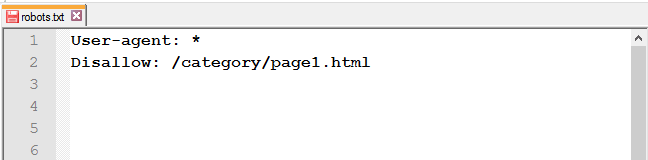
Закрити певну сторінку або файл: вкажіть URL без хосту.
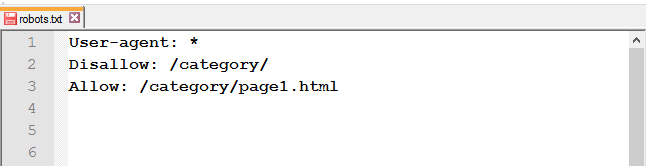
Відкрити доступ до сторінки із закритої папки: після Disallow використовуйте правило Allow.
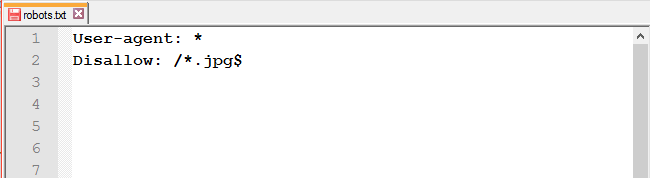
Заборонити доступ до файлів одного типу: щоб заборонити до обходу однотипні файли, скористайтеся спеціальними символами * і $.
Адреса Sitemap у robots.txt
Якщо на сайті є файл Sitemap, вкажіть у відповідній директиві адресу до нього. Якщо ж карт сайту кілька, пропишіть усі.

Це правило враховується роботами незалежно від його місця розташування.
Директива Host для Яндекса
UPD: 20 березня Яндекс офіційно оголосив про скасування директиви Host. Детальніше про це можна прочитати в блозі Яндексу для вебмайстрів. Що тепер робити з директивою Host:
- видалити з robots.txt;
- залишити – робот ігноруватиме її.
В обох випадках потрібно налаштувати 301 редирект.
Роботи Яндексу підтримують robots.txt з розширеними можливостями. Інструкція Host є однією з них. Вона вказує на головне дзеркало сайту.
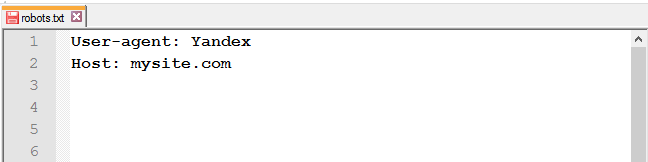
Важливо:
- 1. використовувати www (якщо так починається адреса сайту);
- 2. використовувати HTTPS (якщо сайт на захищеному протоколі, якщо ні – HTTP годі й прописувати).
Як і з Sitemap, місце розташування правила не впливає на роботу робота, воно може бути зазначено як на початку файлу, так і в кінці.
Некоректно прописана директива Host ігнорується роботом.
Crawl-delay
UPD: ПС Яндекс також відмовився від обліку Crawl-delay. Детальніше у блозі Яндексу для вебмайстрів.
Замість директиви Crawl-delay можна налаштувати швидкість обходу у Яндекс.Вебмайстрі.
Директива Crawl-delay вказує час, якій роботи повинні витримувати між завантаженням двох сторінок. Ця інструкція значно знизить навантаження на сервер, якщо у нього є проблеми з обробкою запитів.
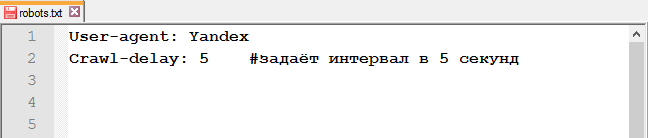
Рядок з Crawl-delay повинен знаходитися після всіх директив з Allow і Disallow.
Оскільки Google це правило не враховує, для гуглботу є інший метод зміни швидкості сканування.
Clean-param
Для виключення сторінок сайту, які містять динамічні (GET) параметри (наприклад, сортування товару або ідентифікатори сесій), використовуйте директиву Clean-param.
Наприклад, є такі сторінки:
https://mysite.com/shop/all/good1?partner_fid=3
https://mysite.com/shop/all/good1?partner_fid=4
https://mysite.com/shop/all/good1?partner_fid=1
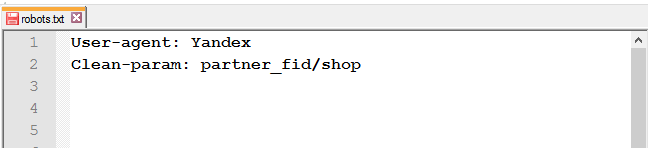
Використовуючи дані з Clean-param, робот не буде перезавантажувати інформацію, що дублюється .
Спецсимволи $, *, /, #
Спецсимвол * (зірочка) означає будь-яку послідовність символів. Тобто, використовуючи зірочку, ви забороните доступ до всіх URL, що містять слово «obmanki».

Цей спецсимвол проставляється за замовчуванням у кінці кожного рядка.

Щоб скасувати *, в кінці правила потрібно вказати спецсимвол $ (знак долара).

Спецсимвол / (слеш) використовується в кожній директиві Allow і Disallow. За допомогою слешу можна заборонити доступ до папки та її вмісту /category/ або до всіх сторінок, які починаються з /category.

Спецсимвол # (решітка).
Використовується для коментарів у файлі для себе, користувачів, або інших веб-майстрів. Пошукові роботи цю інформацію не враховують.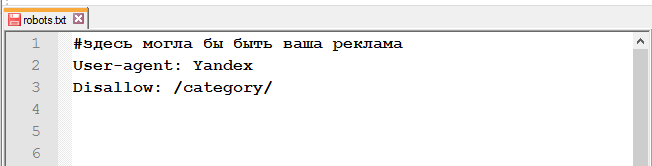
Перевірка роботи файлу
Щоб перевірити файл robots.txt на наявність помилок, можна скористатися інструментами від Google та/або Яндексу.
Як перевірити robots.txt у Google Search Console?
Перейдіть до інструменту перевірки файлу. Помилки та попередження будуть виділені у змісті роботс.тхт, а загальна кількість зазначена під вікном редагування.
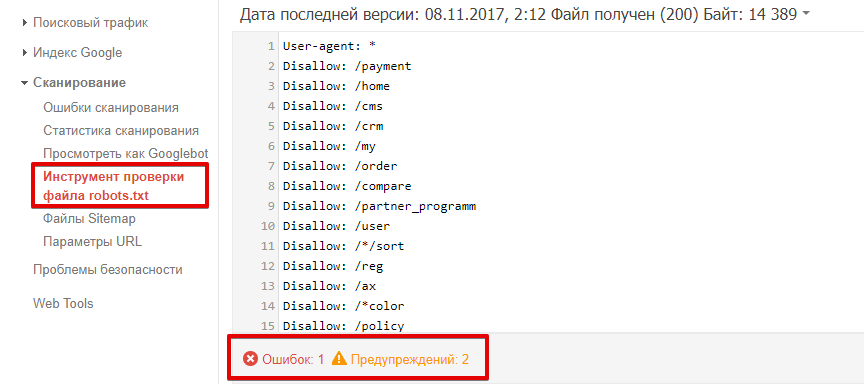
Щоб перевірити, чи доступна сторінка роботу, у відповідному вікні введіть URL сторінки та натисніть кнопку «перевірити». Після перевірки інструмент покаже статус сторінки: чи доступна, чи недоступна.

Як перевірити robots.txt у Яндекс.Вебмайстрі?
Для перевірки файлу потрібно перейти в «Інструменти» – «Аналіз robots.txt».
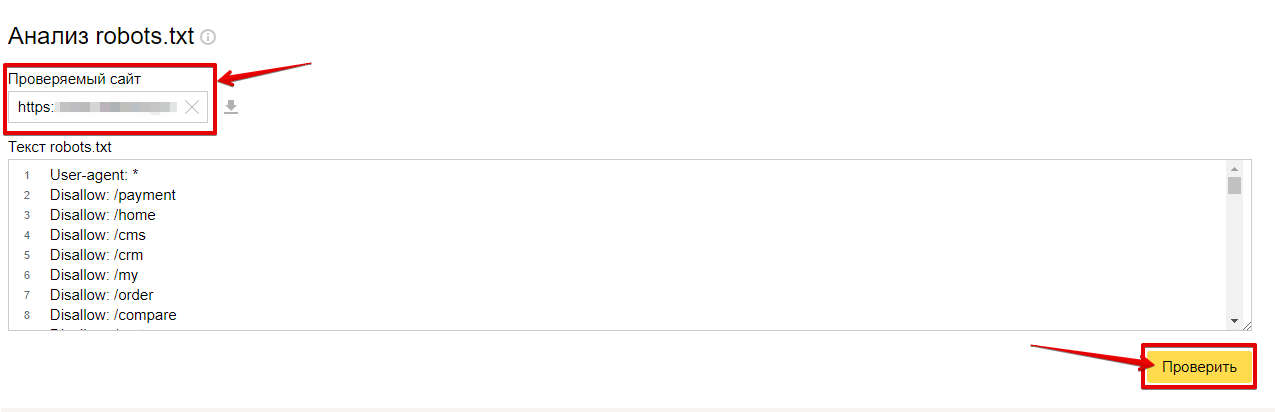
Список помилок, що виникають під час аналізу Роботс.
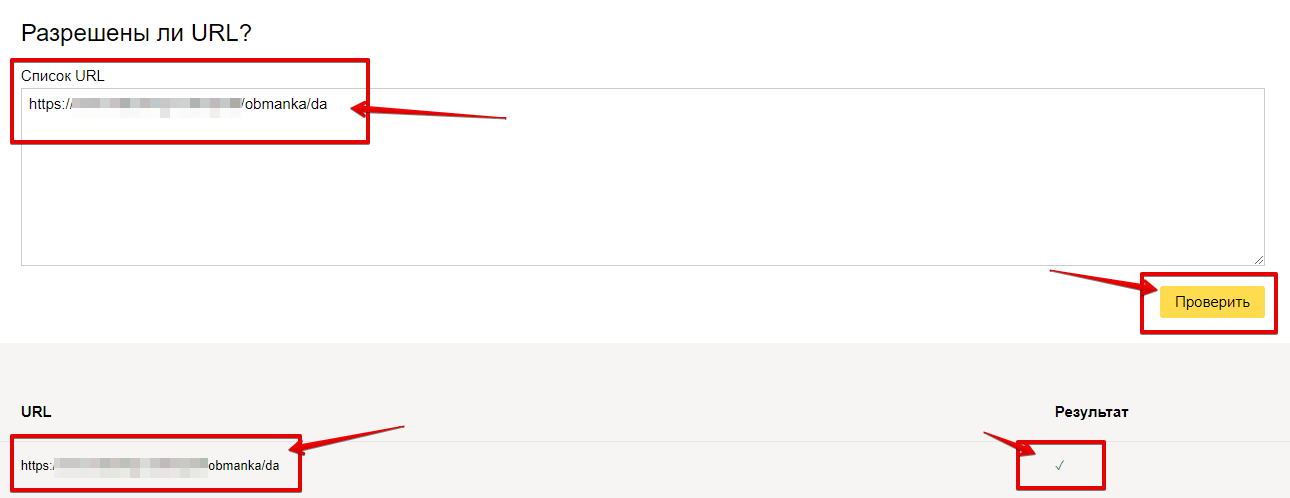
Щоб перевірити, чи дозволений доступ до сторінки, у відповідному вікні введіть URL сторінки та натисніть кнопку «перевірити». Після перевірки інструмент покаже статус сторінки: знак галочки (дозволений) чи буде виведена директива, яка забороняє доступ.
Поширені помилки
-
- неправильне ім’я файлу;
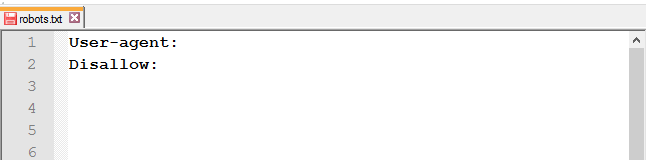
Файл повинен називатися robots.txt. Помилки, допущені в назві файлу: robot.txt, Robots.txt, ROBOTS.TXT. - незаповнений рядок у User-agent;
- неправильне ім’я файлу;
-
- переплутані інструкції чи неправильний порядок директив;

або
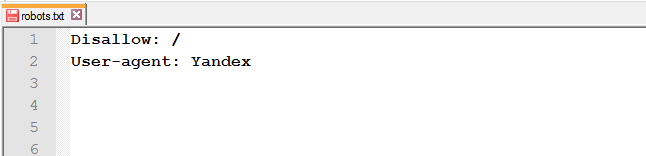
-
- пропуски, розставлені в різних місцях;
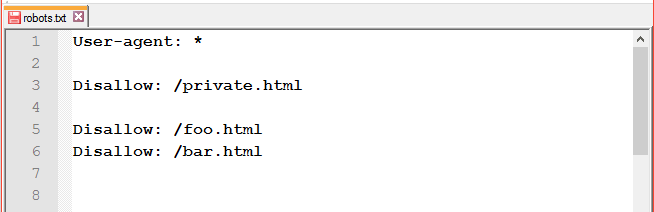
-
- використання великих літер;
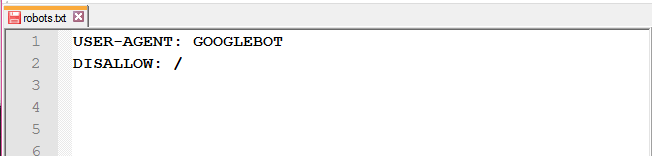
-
- Allow для індексації;
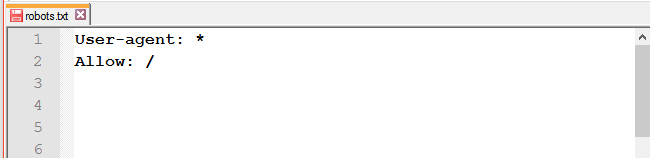 Вона потрібна тільки для перевизначення директиви Disallow в тому ж файлі robots.txt.
Вона потрібна тільки для перевизначення директиви Disallow в тому ж файлі robots.txt. - після доопрацювань весь сайт залишається закритим від індексації;
- Allow для індексації;
-
- закриті від індексації CSS і JavaScript.
Часто зустрічаються сайти, у яких у robots.txt закриті стилі. За підсумком роботи бачать сторінку наступним чином:
- закриті від індексації CSS і JavaScript.
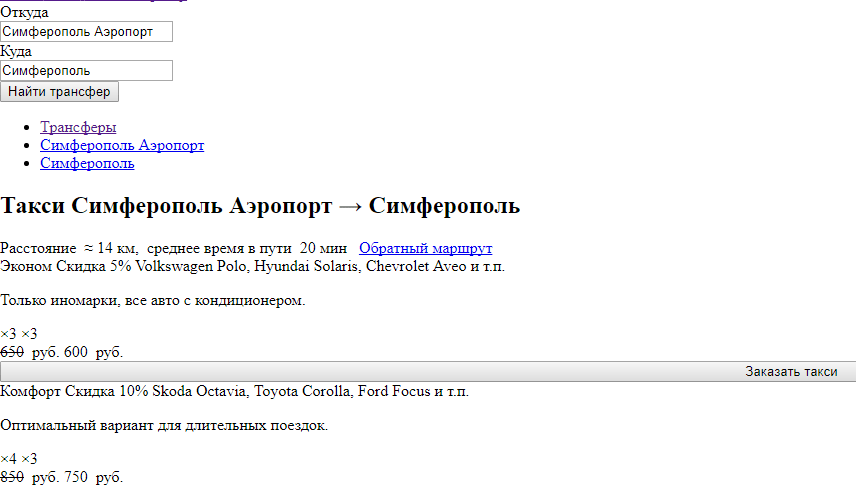
Пошукові системи не рекомендують закривати ці файли від роботів.
Рекомендації Яндексу:

Рекомендації Google:

Robots.txt для різних CMS
Нижче ми пропонуємо розглянути директиви для різних CMS, які часто використовуються. Це не кінцевий варіант файлу robots.txt. Цей набір правил редагується під кожен сайт окремо та залежить від того, що потрібно закрити, а що – залишити відкритим.
Robots.txt для WordPress
Приклад файлу під Вордпресс:
User-Agent: * Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /xmlrpc.php Disallow: /template.html Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content Allow: /wp-content/uploads/ Disallow: /tag Disallow: /category Disallow: /archive Disallow: */trackback/ Disallow: */feed/ Disallow: */comments/ Disallow: /?feed= Disallow: /?s= Allow: /wp-content/*.css* Allow: /wp-content/*.jpg Allow: /wp-content/*.gif Allow: /wp-content/*.png Allow: /wp-content/*.js* Allow: /wp-includes/js/ Host: mysite.com Sitemap: http://mysite.com/sitemap.xml
Robots.txt для Joomla
Приклад роботс для Джумла:
User-agent: * Disallow: /administrator/ Disallow: /cache/ Disallow: /components/ Disallow: /images/ Disallow: /includes/ Disallow: /installation/ Disallow: /language/ Disallow: /libraries/ Disallow: /media/ Disallow: /modules/ Disallow: /plugins/ Disallow: /templates/ Disallow: /tmp/ Disallow: /xmlrpc/ Allow: /templates/*.css Allow: /templates/*.js Allow: /media/*.png Allow: /media/*.js Allow: /modules/*.css Allow: /modules/*.js Host: mysite.com Sitemap: http://mysite.com/sitemap.xml
Robots.txt для Bitrix
Приклад файлу для Бітрікс:
User-agent: * Disallow: /*index.php$ Disallow: /bitrix/ Disallow: /auth/ Disallow: /personal/ Disallow: /upload/ Disallow: /search/ Disallow: /*/search/ Disallow: /*/slide_show/ Disallow: /*/gallery/*order=* Disallow: /*?* Disallow: /*&print= Disallow: /*register= Disallow: /*forgot_password= Disallow: /*change_password= Disallow: /*login= Disallow: /*logout= Disallow: /*auth= Disallow: /*action=* Disallow: /*bitrix_*= Disallow: /*backurl=* Disallow: /*BACKURL=* Disallow: /*back_url=* Disallow: /*BACK_URL=* Disallow: /*back_url_admin=* Disallow: /*print_course=Y Disallow: /*COURSE_ID= Allow: /bitrix/*.css Allow: /bitrix/*.js Host: mysite.com Sitemap: http://mysite.com/sitemap.xml
Висновок
Файл Robots.txt – корисний інструмент у формуванні взаємовідносин між пошуковими роботами та вашим сайтом. За умови правильного використання, він може спричинити позитивний вплив на ранжування і зробити сайт більш зручним для сканування. Використовуйте цей посібник, щоб зрозуміти, як працює robots.txt, як він влаштований і як його використовувати.
P.S. На знак подяки, що дочитали статтю до кінця, ми підготували добірку несподіваних знахідок у файлах robots.txt.
Інтернет-магазин косметики
Майданчик для обміну знаннями, підручниками та ГДЗ
Запрошення на роботу від відомого SEO-сервісу
Ще одне запрошення, але вже в файлі humans.txt
Після 2166 забороняючих, направляючих і дозволяючих директив, у кінці файлу можна виявити малюночок
Еще по теме:
- Як має виглядати технічне завдання на розробку сайту – приклад
- Детальний посібник по файлу Sitemap
- Що таке атрибут rel=”canonical”, коли і як його використовувати?

Оцените мою статью:

 (15 оценок, среднее: 4,20 из 5)
(15 оценок, среднее: 4,20 из 5)
Есть вопросы?
Задайте их прямо сейчас, и мы ответим в течение 8 рабочих часов.