
- (Обновлено:
- 12 минут


Перевірка стану посадочних сторінок
- Лічильник товарів на сторінці, вивантаження значень у Google таблицю
- Підрахунок кількості товарів на сторінці
- Перевірка індексації
Юний SEO-оптимізатор на старті кар’єри зазвичай допомагає старшим SEO-фахівцям, отримуючи від них об’ємні і часто рутинні завдання. У початківця оптимізатора багато роботи, вона не завжди цікава, вимагає багато уваги, сил і часу. Це може вбити весь ентузіазм Junior. Якщо застосовувати маленькі хитрощі, частина завдань можна виконати у десятки разів швидше. У статті я розповім, які прийоми та інструменти використовувати для автоматизації роботи, як заощадити час.
Робота з семантикою
Збір ядра – обов’язковий пункт курсу молодого SEO-бійця. Під час навчання на роботу з семантикою відводиться від 3 до 5 днів. Цього часу може не вистачити, якщо не знати, з чого почати, якої послідовності дотримуватися.
Нижче розповім про те, як прискорити роботу з ядром за рахунок використання неочевидних функцій у знайомих програмах.
1. Збір маркерів
Збір ядра починається з аналізу свого ресурсу та сайтів конкурентів. Щоб охопити всю семантику, за якою можна збирати трафік, варто приділити увагу збору маркерів. Саме вони будуть базою, на підставі якої Key Collector підбере хвости.
Key Collector дає можливість дістати фрази усіх рівнів та їх словоформи. Пропустити кілька маркерів – поступитися конкурентам своїм трафіком. За це оптимізатор, який замовив ядро, точно не подякує.
Приступаємо до збору маркерів: вивчіть головне меню на сайтах конкурентів, подивіться метатеги, анкор внутрішніх посилань, заголовки H. Це основні елементи сторінок, які оптимізують ключами. Там і варто шукати маркери.
Перегляньте ці елементи на своєму сайті. Важливо використовувати синоніми, які підкаже Яндекс, Вордстат або будь-який онлайн-словник синонімів.
Як прискорити
Serpstat
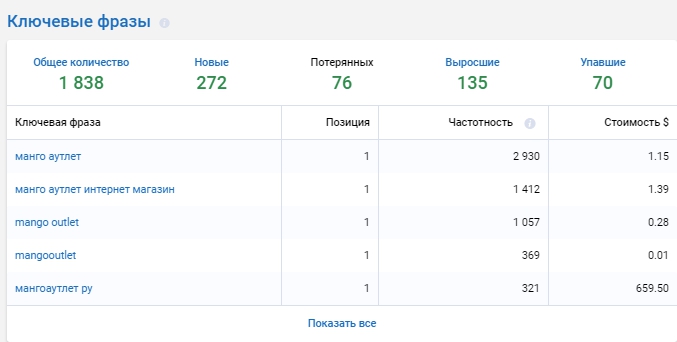
Сервіс покаже, за якими запитами ранжуються сайти конкурентів, частку запитів, за якими ранжуєтесь ви, що було пропущено. Діра у семантиці не дає можливості сайту зайняти лідируючі позиції. Саме запити, за якими видно конкурентів, допоможуть швидко знайти потрібні маркери.
Запити, за якими видно сайт (в тому числі і конкурентів), відображені у звіті «Ключові фрази». Відсіявши вітальні запити, ви зможете знайти ключові слова для просування сайту.
Системи Метрик
Цей метод підходить для пошуку запитів, за якими вже були переходи. Він допоможе не упустити ці ключові фрази у новій семантиці.
Запити, за якими вже були переходи, можна переглянути в GSC. Цей функціонал є в новій версії, відображаються дані за 16 місяців.
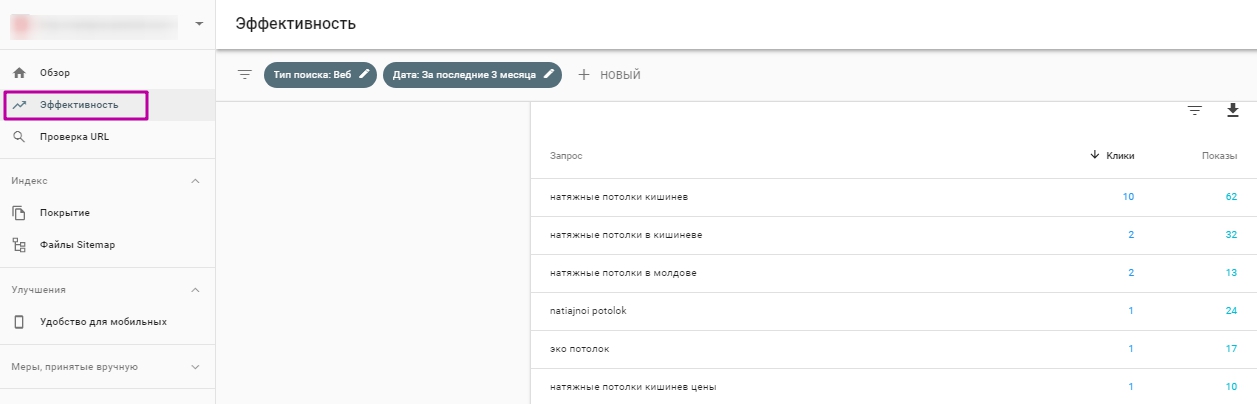
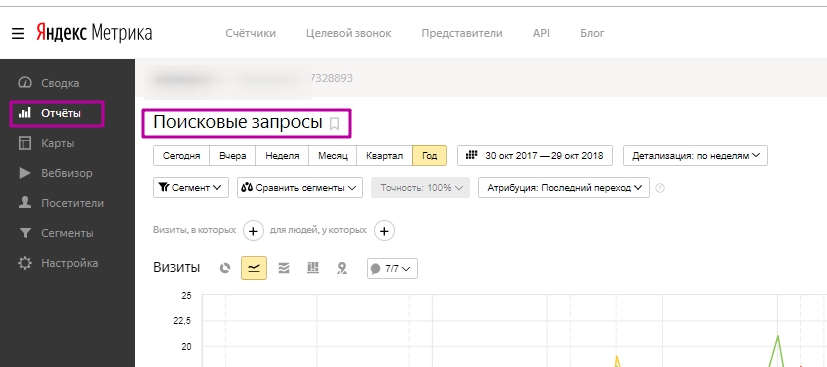
Подивитися запити, за якими були переходи на сайт, можна і в Яндекс.Метрика. Для цього переходимо в «Звіти» → «Пошукові запити».
2. Збір хмари запитів
Зібравши і затвердивши список маркерів, можете приступати до наступного етапу – збору хмари запитів. Не забувайте збирати підказки – це хороше джерело трафіку. ПС формують їх зі справжніх запитів користувачів.
Збір лівої колонки і підказок за великим списком маркерів може зайняти добу.
Як прискорити
Кілька потоків у Key Collector
Для цього потрібно купити додаткові проксі та зареєструвати кілька акаунтів в Яндекс.Директі. Вкажіть їх в пункті «Налаштування» → «Yandex.Direct».
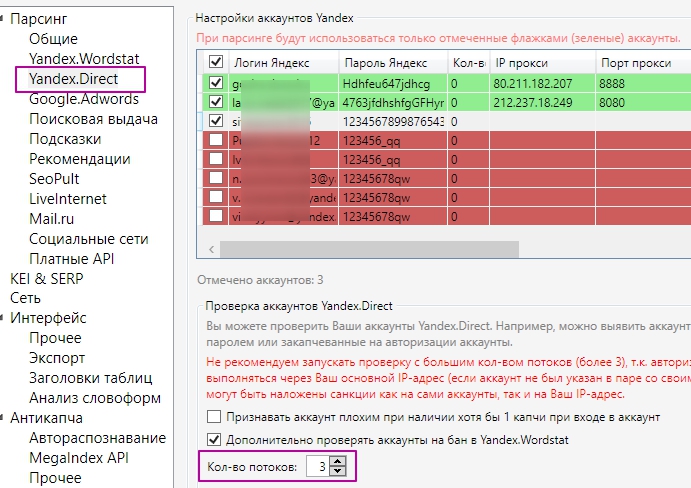
Для кожного облікового запису Яндекса призначте окремий проксі (як показано вище). Це потрібно, щоб запити з усіх потоків не проводилися через один акаунт.
Розробники програми не рекомендують встановлювати більше одного потоку на один IP. Тому підсумовуємо кількість проксі і свій основний IP, записуємо кількість потоків у відповідне поле.
Детальніше – у довідці програми.
Антикапчi
Необхідна, щоб не вводити коди перевірок вручну. Як мінімум, збір буде проходити у фоновому режимі і не зажадає вашої уваги.
3. Частка запитів
Прийшов час чистити ядро. Для цього можна знайти готовий список стоп-слів за вашою тематикою в інтернеті. Однак його доведеться проаналізувати, видалити невідповідні фрази. Це можна зробити, перечитавши всі запити, або…
Як прискорити
Лемматизатор
Можна вивантажити всі слова в онлайн-лемматизатор, віднімати список на предмет сміття і прибрати закінчення сміттєвих слів – отримаємо список стоп-слів для цієї семантики.
Потрібно акуратно видаляти запити, щоб не втратити корисні.
«Аналіз груп» у Key Collector
Ще один спосіб – аналізувати готову семантику прямо у Key Collector.
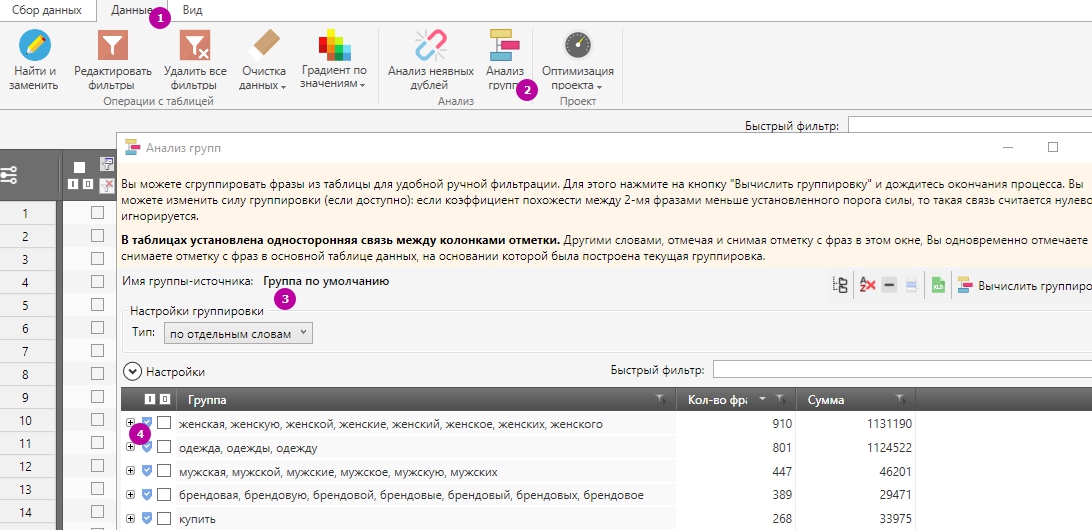
1 – «Дані».
2 – «Аналіз груп».
3 – «Налаштування групування» → «За окремими словами».
4 – Виносимо зайве у стоп-слова.
У цьому випадку видно, яких слів у ядрі більше, яка сумарна частота запитів з ними. Чи можемо відразу додати їх у стоп-слова.
4. Групування готової семантики
Групування ядра або кластеризація (не по топу) – найбільш трудомісткий етап завдання. Групування вручну – довгий і болісний процес, який у підсумку може поступатися за якістю.
Як прискорити
Seo-excel
Це надбудова для SEO-фахівців, яка перетворює зібране ядро за кілька секунд. Вона дозволяє групувати семантику за ІНТЕНТ (тобто за наміром користувача).
Наприклад, є семантика для сайту жіночого та чоловічої брендового одягу старих колекцій, який продається за знижками. Нам потрібно об’єднати ці запити за наміром користувача. Прибираємо слова, які можуть зустрічатися у всіх запитах. Для семантики брендового одягу старих колекцій, яка продається за знижками, це:
- купити;
- ціна;
- інтернет;
- магазин;
- замовити;
- Москва;
- фото;
- вартість;
- бренд;
- дизайнерська;
- аутлет;
- дискон;
- знижки;
- розпродажі.
Ці слова і потрібно «вичавити» з семантики.
Для цього використовуємо інструмент «Вичавлювання»:

1, 2 – Створюємо дві однакові колонки із запитами.
3 – Записуємо слова, від яких потрібно позбутися (без закінчень).
4 – Вказуємо прийменники, від яких теж потрібно позбутися.
5 – Якщо залишити всі галочки, отримаємо назви кластерів транслітом (на латиниці), в інфінітиві й алфавітному порядку.
6 – Колонка з назвами кластерів.
7 – Виконати.
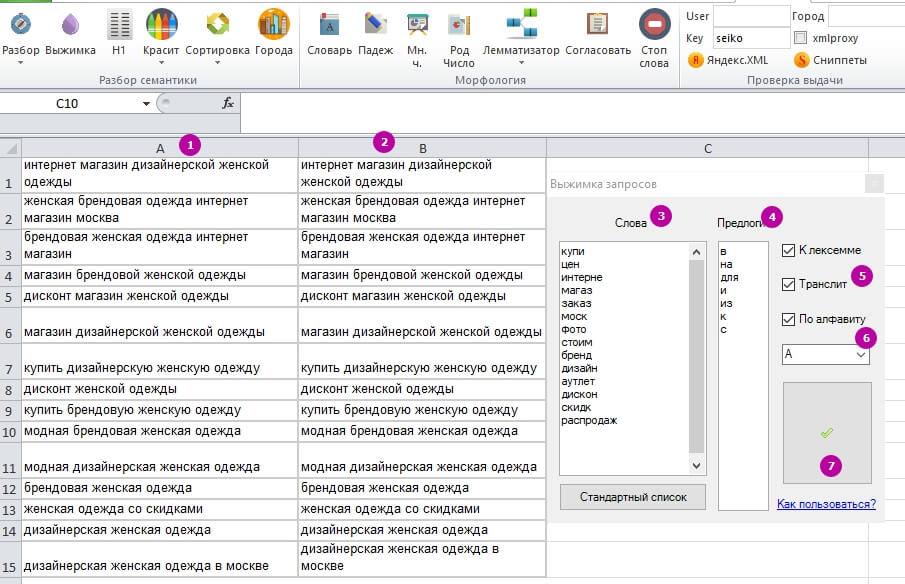
У результаті отримаємо колонку A з назвами кластерів і колонку B з запитами.
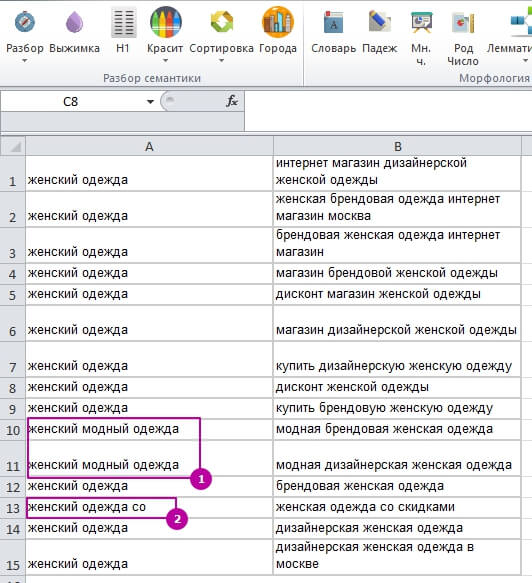
1 – В окремий кластер винесено запити з «модна», оскільки ми не додали це слово у список «Вичавлювання».
2 – Та ж сама ситуація, тільки з прийменником «з».
Дивимося, які ще є зайві слова, за необхідності міняємо/доповнюємо список вичавлювання.
Таким чином ми отримаємо семантику, розбиту на кластери.
Для зручності можна пофарбувати кластери і впорядкувати запити за частотою (самий частотний кластер буде на початку).
Для цього використовуємо «Фарбує» і «Сортування»:
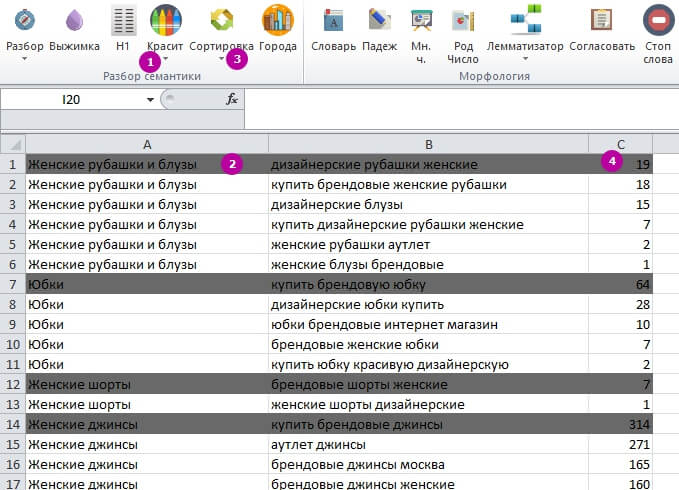
1 – «Фарбує» → «Фарбує всі колонки».
2 – Зафарбовує весь рядок, орієнтуючись на кластер у колонці А.
3 – «Сортування» → «Рядки в кластері».
4 – Отримуємо сортування запитів в одному кластері по спадаючій.
Дивимося, які кластери є, вивантажуємо їх окремим списком за допомогою інструменту «Розбір»:
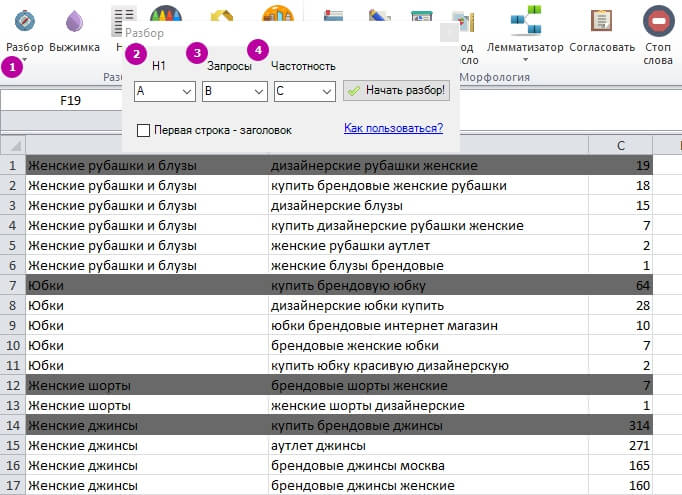
1 – «Розбір» → «Почати розбір».
2 – Вказуємо колонку з назвою кластеру.
3 – Вказуємо, в якій колонці запити.
4 – Вказуємо колонку з частотою.
У результаті отримуємо список кластерів на окремому аркуші.
Перевірка стану посадочних сторінок
Іноді оптимізатор хоче подивитися, скільки товарів є на посадочних сторінках за готовим ядром. Адже асортимент – один з чинників ранжирування, що впливають на просування.
Як це зробити? Відповідь очевидна: відкривати кожну сторінку і рахувати.
Як прискорити
Лічильник товарів на сторінці, вивантаження значень у Google Sheets
Якщо на сторінці є лічильник товарів, можна вивантажити їх кількість у Google Sheets:
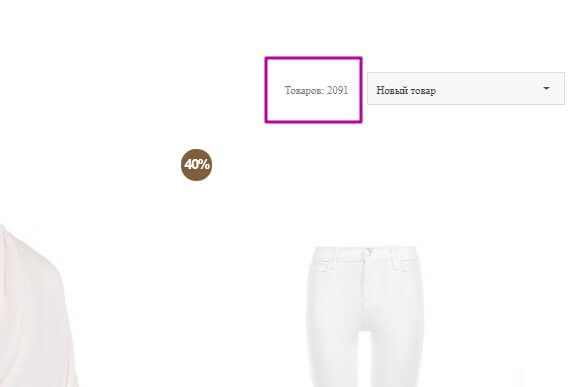
Для цього буде потрібно формула =IMPORTXML.
У цьому випадку шукаємо тег, унікальний для цього лічильника, за допомогою мови Xpath прописуємо шлях до нього:
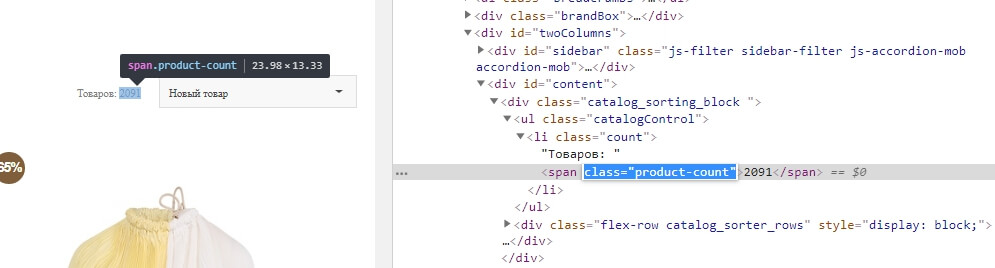
Наприклад, для цього сайту підійшла формула:
=IMPORTXML(J488;"//span [@class='product-count']") де через «//» ми прописали відносний шлях до тегу і до його класу «product-count»
У підсумку отримуємо дані класу «product-count» в документі:
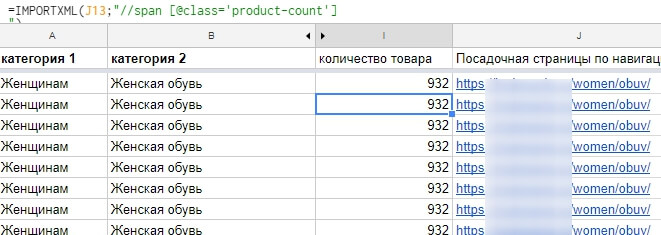
Як користуватися =IMPORTXML та іншими корисними функціями, розказано у статті «20 можливостей Google Sheets, які зекономлять час SEO-оптимізатора: функції, плагіни, макроси».
Підрахунок кількості товарів на сторінці
Часто на сайті немає лічильника товарів. У цьому випадку залишається рахувати картки. Це можна зробити за таким самим принципом. Вибираємо унікальний ідентифікатор для картки товару (у нашому випадку це itemName), додаємо його в формулу, рахуємо кількість таких ідентифікаторів на сторінці через =COUNTA або =СЧЁТЗ.
=СЧЁТЗ(IMPORTXML(E49;"//span[@class='itemName']"))
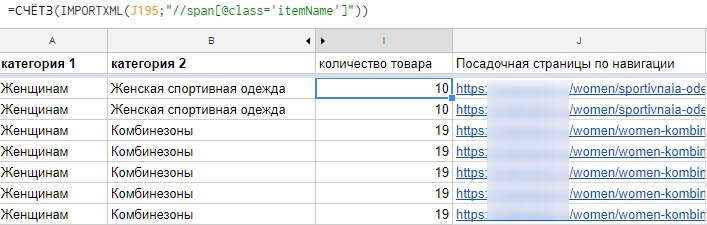
Важливо! Враховуйте пагінацію та блоки рекомендованих товарів. Формула рахує кількість ідентифікаторів тільки на зазначеній сторінці (першій в пагінації). Якщо в категорії занадто багато товарів, які розкидані на 2, 3, 4 і т.д. сторінках, помножте отримане число на кількість сторінок пагінації. Враховуйте, що в категорії можуть виводитися блоки «Ви дивилися» і «Рекомендовані товари». Формула їх теж рахуватиме.
Перевірка індексації
Сторінки, що просуваються, як мінімум повинні бути в індексі. Як відомо, найправильніший спосіб дізнатися, в індексі сторінка чи ні, – перевірити її збережену копію в ПС.
Вручну перевіряти кожну сторінку – довго, особливо для великих сайтів. Формули допоможуть вивести дату останньої збереженої копії сторінки в Google Sheets.
Формула, зазначена нижче, вивантажує дату збереженої копії сторінки:
=IMPORTXML(
СЦЕПИТЬ("http://webcache.googleusercontent.com/search?q=cache:";J194);
"//div[@id='bN015htcoyT__google-cache-hdr']/div"
)
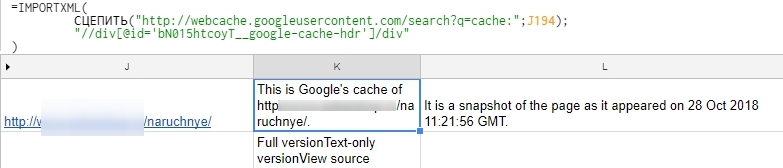
http://webcache.googleusercontent.com/search?q=cache – універсальна адреса кеша Googlе.
J194 – номер комірки, в якій зберігається URL, що аналізується.
<div id=”bN015htcoyT__google-cache-hdr”> – унікальний ідентифікатор блоку з датою на сторінці збереженої копії.
Інформація про дату вивантажується у кілька комірок. У нашому прикладі потрібні дані знаходяться в колонці L.
Xpath разом з =IMPORTXML не раз допоможуть швидко вирішити завдання, тому буде корисним орієнтуватися в їх синтаксисі.
Якщо не розумієте, чому ваш xpath-запит не працює, перевірте його через онлайн-інтерпретатор. Один з них – http://www.xpathtester.com/xpath/.
Створення метатегів
Часто Джунам ставлять завдання прописати метадані для посадочних сторінок. В ідеалі потрібно уважно прописувати унікальні метатеги для кожної сторінки, однак якщо їх декілька сотень, рекомендуємо використовувати хитрощі.
Як прискорити
Використовувати формули
Наприклад, =СЦЕПИТЬ допоможе об’єднати шаблонні блоки метаданих. Створіть вдалий шаблон, в якому прописані потрібні ключові слова та спецсимволи. Як і для чого додавати спецсимволи в Description, можна дізнатися в статті «Як використовувати спецсимволи в Title і Description для залучення користувачів з видачі».
Плагiн Seo-Exсel
Він передбачає кілька шаблонів для створення Title і Description. Уся принадність у тому, що Seo-Exсel враховує частоту запитів і вкладеність усіх запитів з кластера в один запит (частотність Климова).
Плагін пропонує кілька варіантів шаблонів для Title.
Title «З роздільником»
Для цього використовуємо семантику, розбиту на кластери.
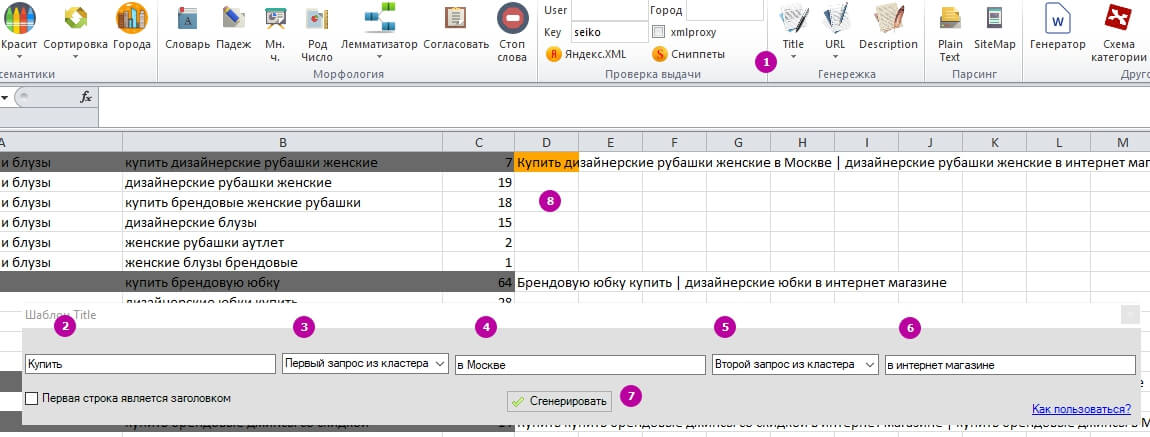
1 – Вибираємо інструмент «З роздільником».
2, 4, 6 – Формуємо патерн, залишаємо слова за замовчуванням або записуємо свій варіант.
3, 5 – Плагін вказує, які слова з кластера він візьме, тому важливо застосовувати сортування запитів за частотою всередині кластера.
7 – Формуємо Title.
8 – Перевіряємо результат.
Більш докладні інструкції з відео є на сайті http://seo-excel.ru/title/.
Особлива цінність цього шаблону – він видаляє дублі. Якщо в перших двох запитах є «купити», плагін залишить тільки один. Тобто, “Купити купити брендову спідницю в Москві | дизайнерські спідниці купити в інтернет-магазині” не буде.
Title «Змінний»
Це другий шаблон для Title. Він також видаляє дублі слів у запитах і пропонує більш широкий функціонал.
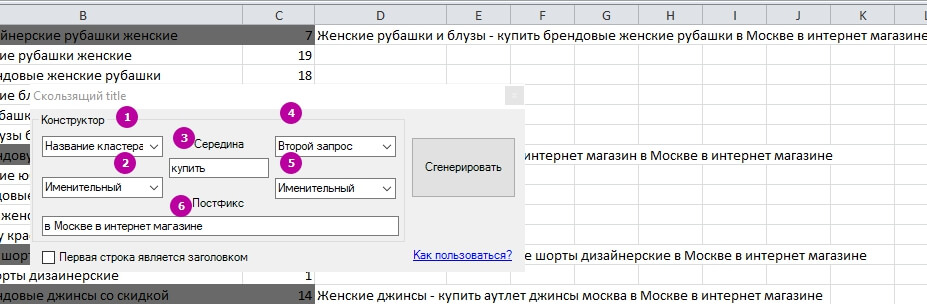
1, 4 – Виберіть, який запит з кластера буде першим, або використовуйте назву кластера.
2, 5 – Задайте відмінок слів у запиті.
3, 6 – Задайте слова для середини і кінця Title або залиште за замовчуванням.
Частотнiсть Климова
Частотність Климова – алгоритм для розрахунку «вдалості» запиту. Він розраховує, який запит містить найбільшу кількість інших запитів і їх частот. Для розрахунку краще використовувати запити з частотою «[!]» (Вона враховує і порядок слів у запиті).
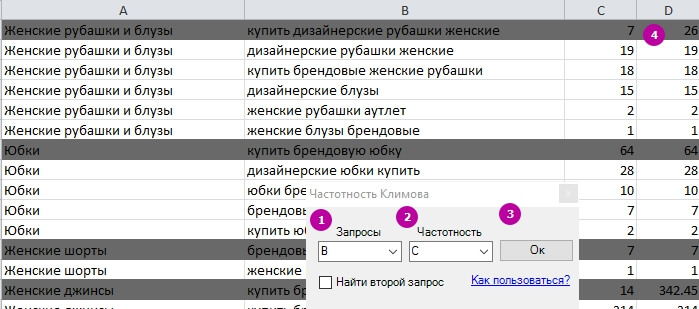
1 – Вказуємо, в якій колонці знаходяться запити.
2 – Колонка з частотами.
3 – Натискаємо «Ок».
4 – Отримуємо розрахунок частотності.
Детальніше про алгоритм в довідці.
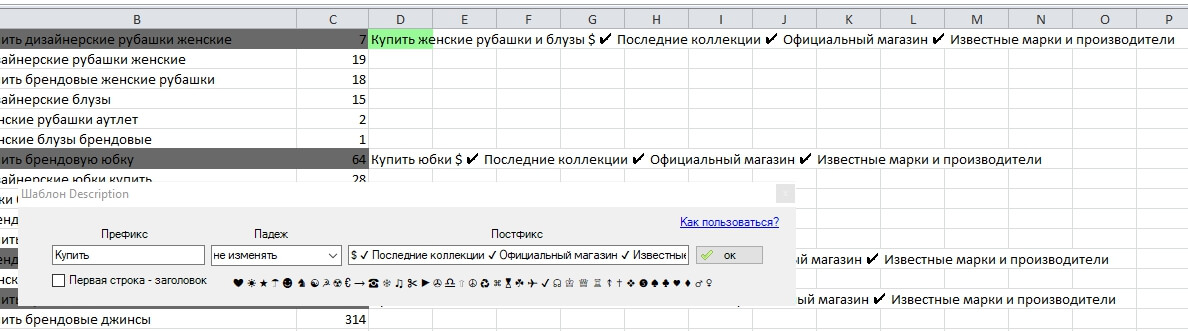
Шаблон для генерації Description
Шаблон для формування Description не такий багатий, проте можна задати префікс і постфікс зі спецсимволами, а також вибрати відмінок для відмінювання назви кластера.
Технічний аудит
Робота з парсером
Будь-який технічний аудит починається з парсингу. Для аудитів великих сайтів вам, швидше за все, може знадобитися сканування окремих карток товарів або категорій.
Наприклад, потрібно сканувати URL категорії жіночих товарів. Вони знаходяться в папці /women/:
Як прискорити
Сканувати окрему категорію, виділивши її регулярним виразом
Для цього найзручніше використовувати популярні парсери і виділяти категорії спеціальними виразами.
Ознайомитися з популярними парсерами і знайти кращий для себе можна в статті «Огляд ТОП-6 парсеров сайтів».
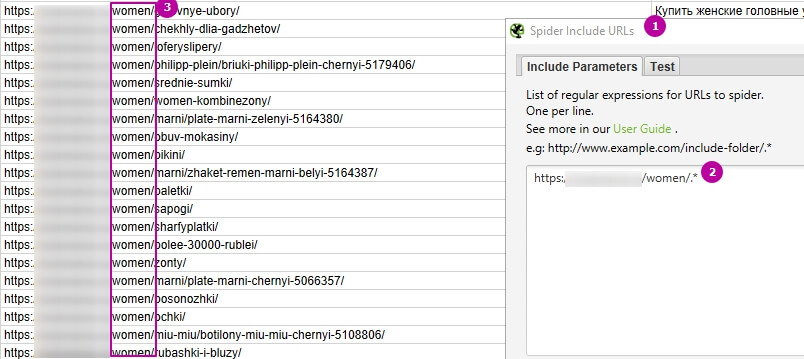
Наприклад, перед скануванням в Screaming Frog потрібно вказати, яка категорія потрібна, в «Configuration» → «Include».
1 – «Configuration» → «Include».
2 – Простим регулярним виразом виділяємо, які URL потрібно сканувати.
3 – Після запуску сканування з урахуванням зазначених правил отримаємо список адрес з будь-яким вмістом після /women/.
Може стати в нагоді зворотна функція «Configuration» → «Exclude» – виключення певної категорії при скануванні: «Configuration» → «Exclude».
Робота з Google Analytics
Під час технічного аудиту може знадобитися інформація про сторінки з Get-параметрами певної категорії. Щоб зрозуміти, закривати їх від роботів чи ні, потрібно оцінити трафік, який вони збирають.
У цьому випадку нам знадобиться GA і його підтримка регулярних виразів. Сторінки з Get-параметрами зазвичай відрізняються від інших URL наявністю «?» в адресі. Наприклад, нас цікавлять адреси такого типу: https://www.site.ru/org-biz/?cur_cc=250.
Їх допоможе знайти формула «org-biz\/.*\?»
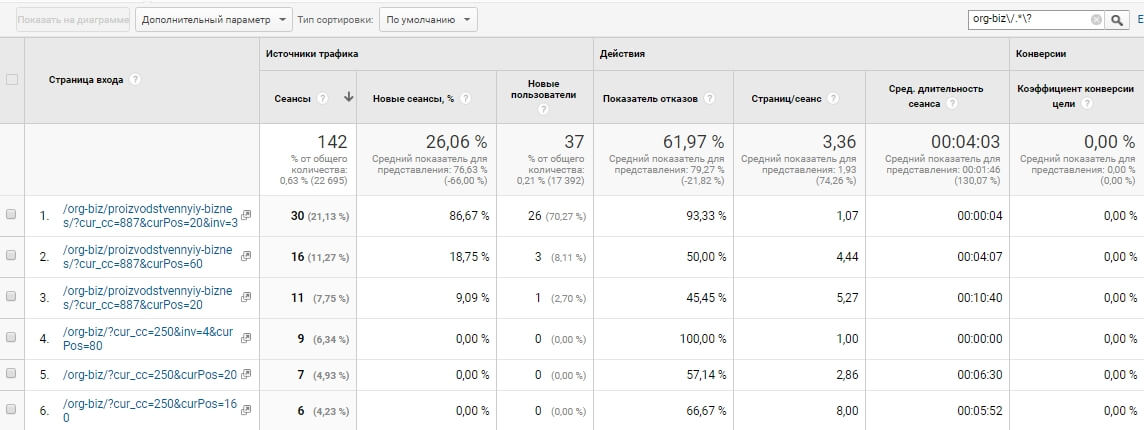
Розбираємо формулу:
org-biz – категорія, сторінки якої нам потрібні;
\/ – екранований метасимвол «/»;
\? – екранований метасимвол «?»;
*. – послідовність будь-яких символів «*».
Детальніше про синтаксис можна дізнатися тут: https://support.google.com/analytics/answer/1034324?hl=ru.
Перевірити правопис формули можна за допомогою https://regex101.com/.
Підсумок
Світ не стоїть на місці і, швидше за все, вже придумані інструменти, які можуть вирішити вашу задачу, навіть якщо вона здається дуже простою, щоб хтось писав спеціальний функціонал, та ще й безкоштовно. Однак варто спробувати знайти те, що заощадить час.
У мережі є порівнювач двох текстів, конвертер формату зображень, який за кілька секунд перетворить список колонкою в рядковий список, розділений комою. Щоб прискорити роботу, достатньо всього лише сформулювати потребу і додати «онлайн» в пошуковому рядку.
Еще по теме:
- Нова версія Google Search Console – огляд доступних інструментів. Січень 2019
- Як прискорити виконання завдань – поради, інструменти для SEO-Junior
- Групування запитів за методом подібності ТОПів: опис, кластеризатори

Оцените мою статью:
 (22 оценок, среднее: 5,00 из 5)
(22 оценок, среднее: 5,00 из 5)
Есть вопросы?
Задайте их прямо сейчас, и мы ответим в течение 8 рабочих часов.