
- (Обновлено:


Наш SEO-аналітик Євген Аралов провів безкоштовний вебінар для тих, хто хоче упевнитися в коректній роботі свого сайту або знайти проблемні місця й усунути їх. Ми підготували відео, презентацію і текстову версію його вебінару:
Відеозапис вебінару (18.11.2015)
Презентація «Як провести технічний аудит сайту»
Замовити аудит сайту з інструкціями щодо просування
Текстовий зміст вебінару
Сьогодні поговоримо про технічні помилки.
По-перше, технічні помилки можуть негативно впливати на індексацію і ранжування сайту.
По-друге, якщо у вас різко просів трафік з усіх пошукових систем, вам також слід звернути увагу на можливі технічні помилки. Швидше за все, причина у них.
Будуємо нашу презентацію таким чином:
– Погана індексація і ранжування
- Пошук дублів і сміттєвих сторінок
- Час і швидкість завантаження сайту
- Перевірка індексації важливих областей сторінки
– Трафік різко впав
- Проблеми з доступністю сайту
- Налаштування редиректу
- Віруси
ПОГАНА ІНДЕКСАЦІЯ ТА РАНЖУВАННЯ
1. Пошук дублів і сміттєвих сторінок.
Чому дублі негативно впливають на ранжування та індексацію сайту:
– Витрачають краулінговий бюджет
Краулінговий бюджет – це кількість сторінок, яку за раз може проіндексувати робот пошукової системи. У кожного сайту свій краулінговий бюджет, впливає на нього велика кількість факторів від популярності сайту, швидкості завантаження до к-ті нових сторінок, що з’явилися .
Тобто робот зайшов на сайт, за раз він може проіндексувати, наприклад, 10 сторінок. І замість того, щоб індексувати нормальні сторінки, він індексує дублі. Те ж саме і зі сміттєвими сторінками, які до основного контенту ніякого стосунку не мають.
– Чи впливають на релевантність
Якщо в нас є 2 однакові сторінки, їх релевантність може змінюватися. Тобто по одному запиту може виходити то одна сторінка, то сторінка-дубль – ми прокачуємо одну сторінку, а виходить зовсім інша. Ми не можемо контролювати цей процес, і це дуже заважає просуванню сайту.
– Розмивається статична вага сайту
Тобто ми будуємо якусь перелінківку, у нас є певна структура, і зайва вага йде на ці дублі. Чим більше дублів, тим менше сторінка передає вагу.
– Чи можуть значно знижувати трафік
У Google дублі часто можуть стати причиною різкого зниження трафіку. Були випадки, коли трафік урізався з 15 тис. до 1 тис. Після усунення дублів трафік відновлювався.
Поширені дублі:
Основні – це сторінки:
- з www і без www
- з index.html і без
- сторінка доступна зі слешем і без: site.ru/ і site.ru
Вирішується проблема легко – просто ставимо 301 редирект. Це варто робити на самому початку, під час запуску сайту, тоді жлдних проблем не буде.
Приклад з www на без www:
Options + FollowSymLinks
RewriteEngine On
RewriteCond %{HTTP_HOST} ^www\.(.*) [NC]
RewriteRule ^(.*)$ https://%1/$1 [R=301,L]
Важливий момент для Яндексу: Під час налаштування головного дзеркала (коли ми вибираємо, показувати пошуковику домен з www або без www, обов’язково вказуйте в robots.txt Host – Host: site.ru (вказали головне дзеркало без www).
Для Google просто налаштовуємо 301 редирект.
Інші види дублів:
1. Дублі сторінок з GET-параметрами
Приклад: site.ru/page1/?prm=fetxie
Зазвичай в інтернет-магазинах такі дублі виходять у результаті різних угруповань (за рейтингом, популярністю т.д.) і фільтрів. Такі сторінки часто потрапляють в індекс.
Питання: Тобто фільтри в інтернет-магазині – це дублі? Якщо вони потрапляють в індекс і така інформація немає попиту, то так. Припустимо, ми фільтруємо за ціною – такий фільтр, швидше за все, буде дублем, фільтри за брендом- вже немає, але тоді потрібно формувати окрему сторінку з нормальним ЧПУ-урлом. З фільтрами був такий приклад – на сайті з оренди яхт були фільтри, виходило так, що велика частина одних і тих самих човнів за фільтрами перетиналася, тобто за фактом формувалися дублі. У кожного з’являвся свій параметр, він потрапляв у індекс, плодилися однакові сторінки.
Як позбутися: додаємо GET-параметри в robots.txt: Disallow:? Prm або реалізуємо сортування (фільтри) через ajax – тоді не будуть додаватися додаткові параметри в URL.
2. Дублі карток товарів
Найпоширеніший вид – один товар у різних кольорах. Наприклад, site.ru/product-red.html; site.ru/product-green; (плаття «Модель» червоне, плаття «Модель» зелене)
У таких випадках рекомендую об’єднати картки товарів з можливістю вибрати колір на сторінці. Винятком може бути, якщо у запитів висока частота. Наприклад, ви бачите за вордстат, що для запитів «плаття коротке зелене» і «плаття коротке червоне» висока частота – тоді, можливо, варто розділяти їх, але щоб хоча б якось уникалізувати, щоб не було таких дублів.
Ще одна поширена ситуація – один товар знаходиться в декількох категоріях. Наприклад, сукня знаходиться в категорії «Сукні» і «Короткі сукні». Нічого поганого в цьому немає, але якщо URL формуються таким чином:
site.ru/platya/product1.html; site.ru/korotkie-platya/product1.html
то це треба виправляти.
Як виправити: переробка структури, 301 редирект; один товар – один url (вибираємо одну категорію)
Питання: Чи можна використовувати rel = canonical в цьому випадку? – Якщо для карток товарів ви будете використовувати rel = canonical, ви можете в них заплутатися – що на що направляти, але загалом проблему це вирішить.
3. Часткові дублі – сторінки, у яких велика частина контенту перетинається.
Цим страждають блоги, наприклад, дублюються анонси. З одного боку в цьому нічого такого немає, так влаштовані движки, але ми рекомендуємо писати унікальні анонси до статей блогу.
Те ж саме може стосуватися карток товарів. Наприклад, у мене був медичний сайт, на сторінках різних лікарів був великий блок з описом послуг (близько 10 тис. символів), який повторювався, унікального опису в порівнянні з цим блоком було мало – близько 1,5 тис. знаків. Виходить, що всі картки є дублями, незважаючи на те, що є якийсь унікальний контент – у такому випадку треба вносити зміни.
Питання: Як вирішили проблему з дублями на медичному сайті? Було 2 приклади з дублями на медичних сайтах. У першому прикладі (сайт запису до лікарів) закривали від індексації часткові дублі або прибирали зовсім – зробили так, щоб основного унікального контенту було більше. У другому прикладі дублювалися описи мед. препаратів (у деяких ліків різні назви) – під кожну власну назву були створені сторінки. У конкурентів було те ж саме, тільки були додані відгуки і була можливість купити препарати. Ми поліпшили унікальність цих сторінок.
Як вирішити: закриваємо від індексації за допомогою ajax або пишемо унікальні анонси/тексти.
CANONICAL:
Щоб уникнути непорозумінь у вигляді GET-параметрів та інших підстановок в URL, рекомендується використовувати rel = “canonical”.
Даний атрибут показує пошуковій системі канонічний URL, який потрібно індексувати.
Рекомендуємо додати на все статичні сторінки (для сторінок результатів пошуку не підходить) для попередження появи різних дублів:
- дублі через різні регістри: site.ru/page1 і site.ru/Page1
- дублі через utm-міток: *utm_source=, /*utm_campaign=, /*utm_content=, /*utm_term=, /*utm_medium=
- різні дублі сторінки угруповань: /*sort, asc, desc, list=*
Таким чином, наприклад, для сторінки site.ru/page1 rel = “canonical» буде виглядати наступним чином:
<Link rel = “canonical» href = “site.ru/page1” />
З приводу того, що сторінки іноді не індексуються з rel = “canonical» – Google досить добре все це «їсть», з Яндексом бувають проблеми, але останнім часом їх все менше.
Детальніше про rel = “canonical» можна прочитати за наступними посиланнями:
https://support.google.com/webmasters/answer/139066?hl=ru
https://help.yandex.ru/webmaster/controlling-robot/html.xml#canonical
ЯК ШУКАТИ ДУБЛЬ?
Найпростіший спосіб знайти серйозні, повні дублі – пошук за title.
Зазвичай у таких дублів title однакові.
1) Можемо зайти в Google Search Console – у вкладці «Оптимізація Html» побачимо кількість дублів:
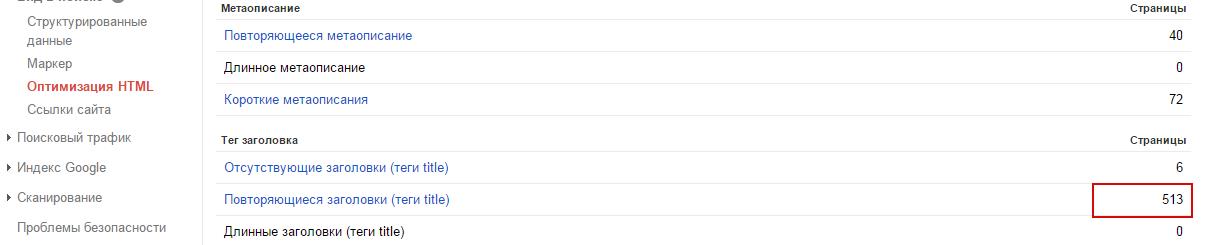
Єдине – не обов’язково вони в індексі, але, принаймні, ми точно знаємо, що у нас є якісь дублі.
2) Можемо парсити сайт за допомогою таких програм, як Screaming Frog або Netpeak Spider.
По суті, вони виконують одну й ту ж функцію – скачують всі сторінки і підсвічують дублікати title.

Зліва – Screaming Frog (платно, бескощтовно 500 урлів). Натискаєте Duplicate – і отримуєте всі сторінки з дублікатами
Праворуч – Netpeak Spide (безкоштовно, але менше функціоналу). Так само вибираєте «Дублікати» – і отримуєте список.
Знову ж, не факт, що всі ці сторінки в індексі, але ці дублі можуть витрачати ваш краулінговий бюджет, робот на них заходить, і ви втрачаєте час.
3) Через пошуковий оператор intitle.
Припустимо, ви припускаєте, що в якийсь категорії у вас можуть бути дублі, або ви хочете перевірити – взяти основні категорії і, ввівши таку конструкцію в пошуку Яндексу або Google, побачити сторінки, які дублюються за title:

Це зручно, коли ви добре знаєте свій сайт.
4) Через пошуковий оператор inurl.
Такий спосіб зручний, коли ви працюєте з великим сайтом і погано з ним знайомі або знаєте сайт, але ніколи такого не робили.
Вводите site.ru (ваш домен) / inurl (категорія)
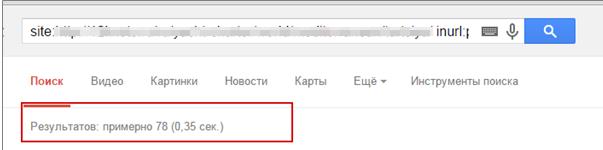
Вручну переглядаємо, чи є якісь дублі за категоріями.
Ручна робота – найкраща, бо, переглядаючи кожну сторінку, ви реально можете побачити те, що в індексі, автоматизація не завжди на 100% дає достовірний результат.
Якщо ви знаєте, що у вас є якісь певні параметри, наприклад, ви їх бачите, коли користуєтеся групуваннями, то можете за оператором inurl вбити цей параметр, як на нижньому скріншоті, і ви отримаєте всі урли, які є в індексі з цим параметром:
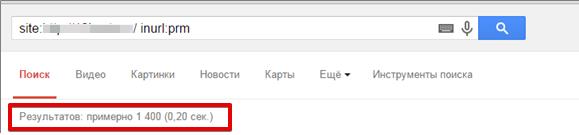
Серед них виявити дублі, якщо вони є, не буде труднощами.
ЯК ШУКАТИ ЧАСТКОВІ ДУБЛІ
1) Пошук за фрагментами тексту
Беремо фрагмент тексту і вбиваємо в пошук з оператором site: і відразу побачимо, чи є у нас якісь перетини за текстом.
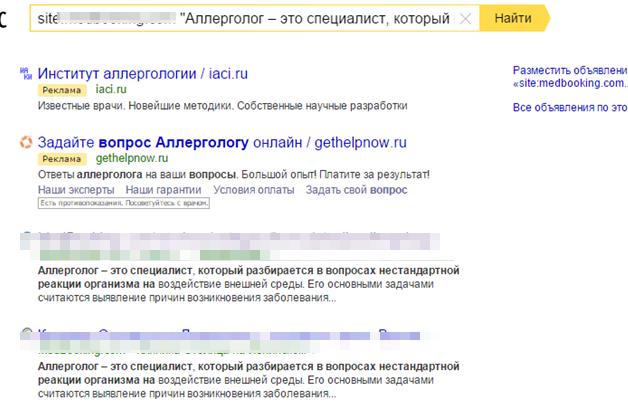
Не варто брати тільки 1 фрагмент, беріть кілька фрагментів зі сторінки, дивіться, чи є перетину за усіма фрагментами.
2) За допомогою сервісу seoto.me
Часткові дублі він знаходить «на ура». Знаходить те, що вручну не завжди можна помітити, показує, який відсоток тексту і яка кількість символів перетинається.

Сервіс платний, але показує близько 30% всього сайту, для оцінки вам цього буде цілком достатньо.
СМІТТЄВІ СТОРІНКИ
До них відносяться:
– Технічні сторінки:
- Кошик /cart/
- Реєстрація /register/
- Користувачі /user/
- Файли /files/
За замовчуванням повинні бути закриті від індексації.
– Порожні сторінки (сторінки з помилками, порожні, незаповнені картки товарів):
В принципі, будь-які сторінки з малою кількістю контенту можна вважати сміттєвими.
Як знайти:
– Пробиваємо за пошуковим оператором inurl
– Шукаємо сторінки з малою кількістю контенту (Screaming Frog) – можемо оцінити за кількістю слів. Якщо контенту мало, треба подивитися, що це за сторінки
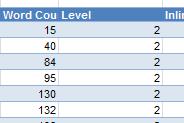
15-40 слів – це дуже мало
Якщо це технічні сторінки, ви просто закриваєте їх від індексації, якщо це док-файли, в яких немає цінної інформації, то їх теж можна закривати.
Якщо це важливі сторінки, і ви хочете, щоб вони індексувалися, то закривати від індексації їх не варто.
– Сміттєві піддомени (часто тестові дублі)
Ми на піддоменах тестуємо якісь свої движки, або просто програміст щось робив на них, в результаті отримуємо піддомени, які є практично повними дублями всього сайту.
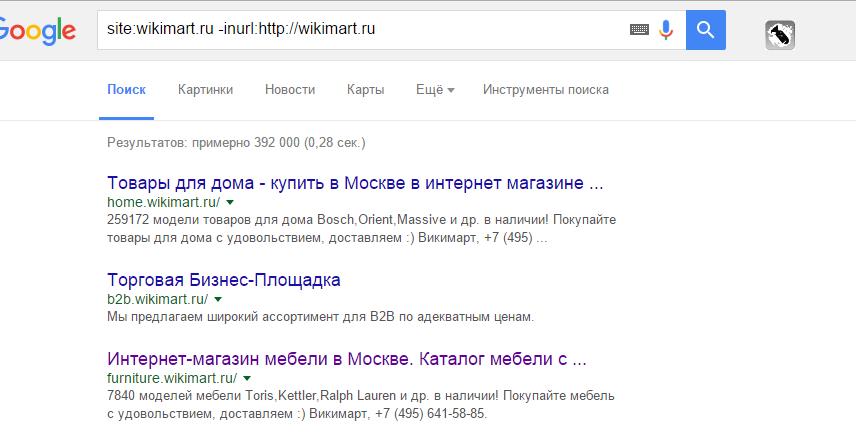
Як їх знайти?

Беремо основний домен, виключаємо відомі нам домени (як на прикладі: ~~ host: wikimart ~~ host: appliances.wikimart). Тобто методом виключення ми знаходимо, чи немає якихось технічних піддоменів.
Те ж саме в Google. Пишемо так:
ШВИДКІСТЬ ЗАВАНТАЖЕННЯ САЙТУ
Це фактор ранжування сайту (Google дуже педантично до нього ставиться), і він може негативно позначатися на краулінговому бюджеті (якщо швидкість завантаження сайту низька, то і краулінговий бюджет стає менше).
Загальні вимоги:
– Час відгуку серверу (як швидко сервер відповідає на запит від браузера) – до 300 мс
– Час завантаження сторінок – близько 3-5 с
Як перевіряти?
За допомогою інструментів:
– Google Analytics
– https://www.webpagetest.org/
– https://developers.google.com/speed/pagespeed/insights/
1. Заходимо в GA – Вкладка «Поведінка» – «Час завантаження»:
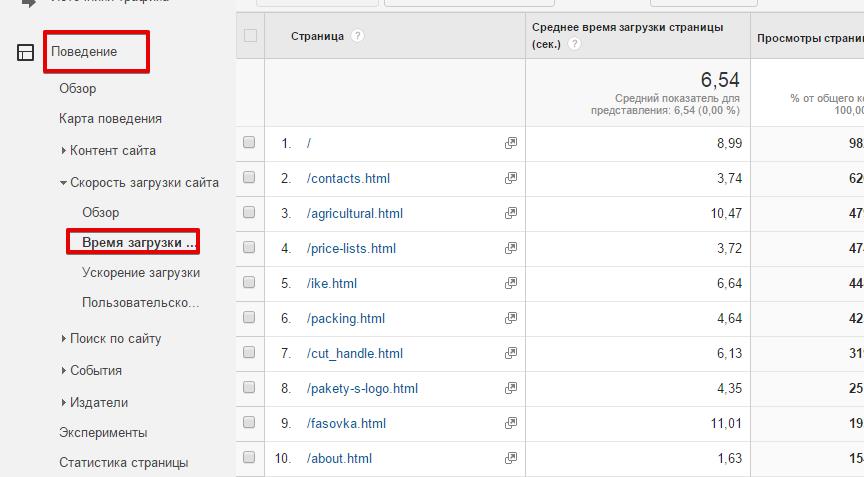
Бачимо, який час завантаження у кожної сторінки за певний період часу. Тут видно, що час завищено: головна сторінка – під 9 с, завантаження прайс-листа нормальна – 3,7 с.
2. Беремо ці сторінки і заганяємо в сервіс https://www.webpagetest.org/, який нам покаже, в чому причина такого повільного завантаження (можливо, багато запитів, великі файли.
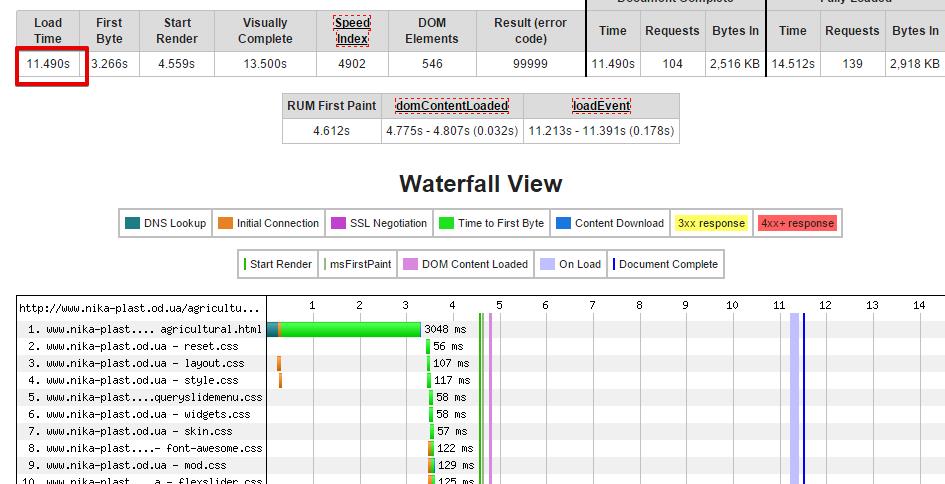
Показане повне завантаження сайту – 11,49 с, користувач отримав картинку через 13 с. Це дуже багато, тобто ніякої конверсії з цього переходу ми не отримаємо, швидше за все, користувач так довго чекати не буде і просто закриє сторінку, а наш сайт ще і погано ранжируватиметься. За кожним запитом ми бачимо, скільки витрачається часу і на що.
Що є що:

Ці смужки різного кольору позначають різні параметри.
- Пошук DNS (темно-зелений) – грубо кажучи, це час конвертації домену в IP-адресу. Ми вплинути на цей параметр не можемо, але звертати увагу на нього теж варто.
- TCP-підключення (помаранчевий колір) – перед тим як відправити запит серверу, необхідно створити TCP-з’єднання. Повинно бути створено тільки на перших полях (великої кількості таких смужок бути не повинно). Інакше будуть проблеми з продуктивністю.
- Час отримання першого байта (салатовий) – скільки часу браузеру потрібно для прийому першого байта, тобто отримання відповіді від сервера під час запиту конкретного URL.
- Завантаження контенту (синій) – скільки часу браузер витрачає на завантаження контенту.
Ми можемо оптимізувати швидкість завантаження по висоті і по ширині (в висоту – запити, в ширину – швидкість відповіді)
Оптимізація по ширині:
– Якщо багато оранжевого:
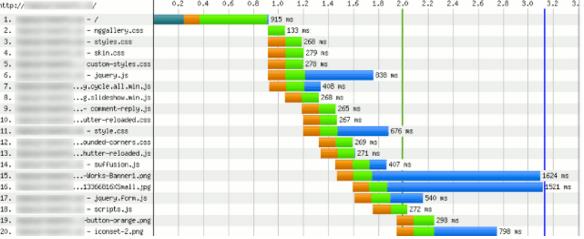
Швидше за все, у вас не включене постійне з’єднання. Передусім потрібно увімкнути (подробнее). Хоча це досить рідкісне явище.
– Якщо багато синього:
![]()
Цей випадок поширений. Якщо у вас довгі сині смуги, значить, у вас довго вантажаться скрипти, картинки. Наприклад, як видно на скріншоті, файл формату png – довга синя смуга, картинка довантажувалась майже 1,6 с. Це багато і її треба оптимізувати.
– Якщо багато зеленого – браузер довго чекає передачі даних від серверу.
Варто задуматися про зміну хостингу або налаштування CDN (мережа доставки контенту).
Детальніше – https://habrahabr.ru/company/sports_ru/blog/198598/.
Загальні рекомендації:
– Оптимальний розмір зображень – до 100 Кб (якщо це можливо)
– Стискаємо скрипти і стилі в gzip (усі технології в інтернеті описані)
– Налаштовуємо CDN
Наше завдання – зменшити вагу сторінки. Чим менше вага сторінки, тим швидше вона буде завантажуватися.
Оптимізація по висоті
У цьому випадку нам треба скоротити кількість HTTP-запитів.
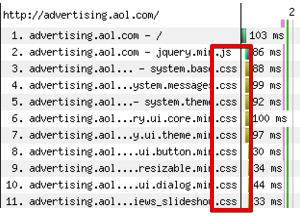
Часто можна бачити, коли 10 СSS знаходяться в шапці або, ще гірше, в футері сайту. Під час кожного звернення до кожного CSS йде зайвий запит до серверу, сервер віддає цей CSS. Якщо ці СSS великі, то все це дуже затягує завантаження.
Ми повинні стежити за цим, скорочувати кількість HTTP-запитів, зменшуючи кількість скриптів і CSS.
Загальні рекомендації щодо оптимізації по висоті:
– Об’єднуємо CSS-файли
– Об’єднуємо JS
– У верстці використовуємо спрайт
Приклад:
![]()
Цим майже ніхто не займається, тому особливо важливо звертати увагу.
Прискорення рендерингу (прискорювати завантаження сторінки для користувача, тобто її візуальну частину)
– Ставимо CSS вгору (в блок <head>), скрипти опускаємо вниз. Таким чином, коли браузер обробляє всі дані, відразу підвантажує візуальну частину, користувач думає, що сторінка вже завантажилася і починає її переглядати, поки вантажиться все інше.
– Включаємо скрипти асинхронно:
<script async src=”example.js”></script>
Тут же скрипт викачуватиметься асинхронно, не заважаючи обробці HTML-розмітки сторінки.
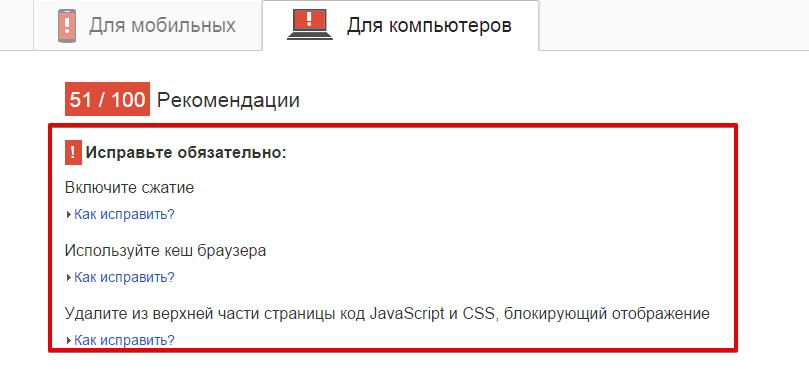
– Прямуємо до рекомендацій сервісу Google Page Speed (як для мобільних, так і для ПК). Він сам стискає скрипти, зображення, тобто ви можете завантажити все готове, прогнавши сайт через нього.
ПЕРЕВІРКА ІНДЕКСАЦІЇ ВАЖЛИВИХ ОБЛАСТЕЙ СТОРІНКИ
Програмісти нечасто звертають увагу на SEO-оптимізацію, через це часто спливають помилки. Буквально недавно до нас прийшов сайт на аудит, на скріншоті видно, як бачив сторінку категорії користувач і як Яндекс:

На відміну від користувача, який бачив картки товарів, Яндекс бачив тільки текст. Все довантажувалось скриптами, скрипти були закриті від індексації, Яндекс скрипти до останнього часу не читав, в результаті вийшло, що на комерційному сайті є тільки текст, і він не ранжируєтся за комерційними запитами.
Обов’язково через збережену копію перевіряйте, як бачить ваш сайт Яндекс.
Те ж саме і в Google – перевіряємо, як бачить сайт GoogleBot, в Search Console:
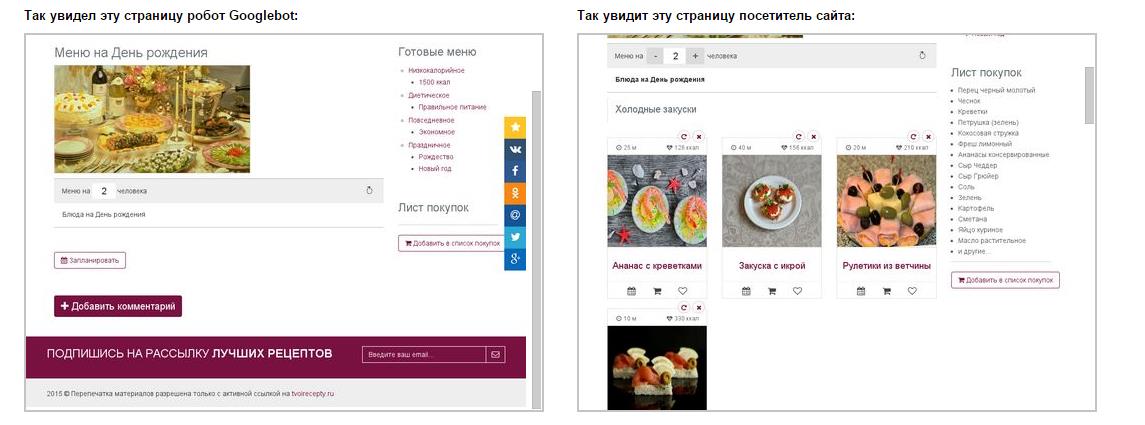
На прикладі користувач бачить картки рецептів, а GoogleBot не бачить, для нього це просто сторінка з однією картинкою (за таке можна отримати бан).
ТРАФІК РІЗКО ВПАВ
З якими технічними проблемами це може бути пов’язано:
1. Є ймовірність, що ваш сайт недоступний або був недоступний якийсь час.
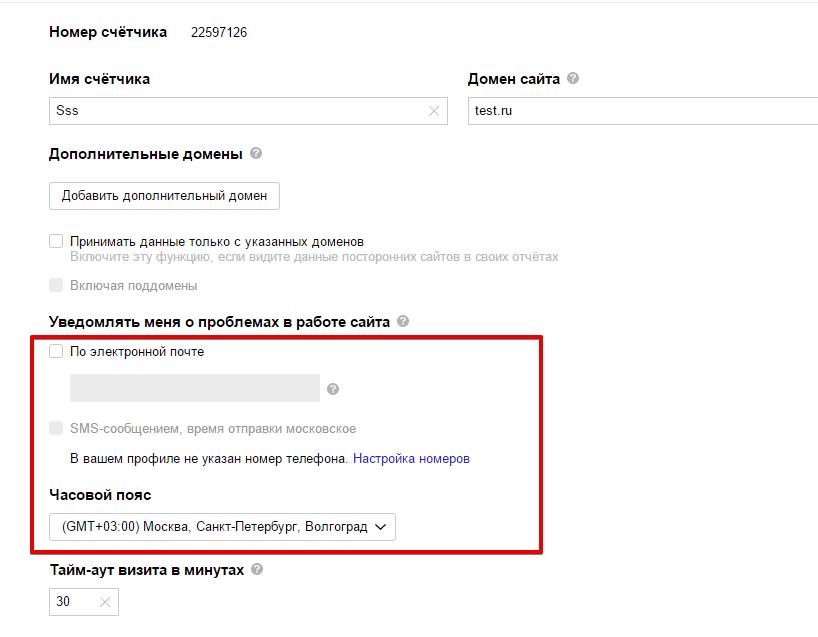
– Щоб контролювати це, налаштуйте в Яндекс.Метриці SMS (e-mail) повідомлення про доступність сайту (Налаштування – Повідомляти мене про проблеми з сайтом):
– Моніторте Search Console – ви будете отримувати повідомлення про проблеми з доступністю:
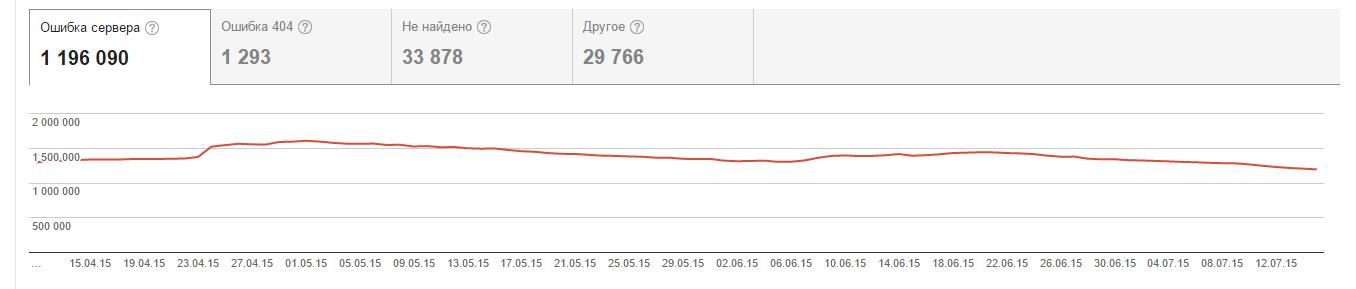
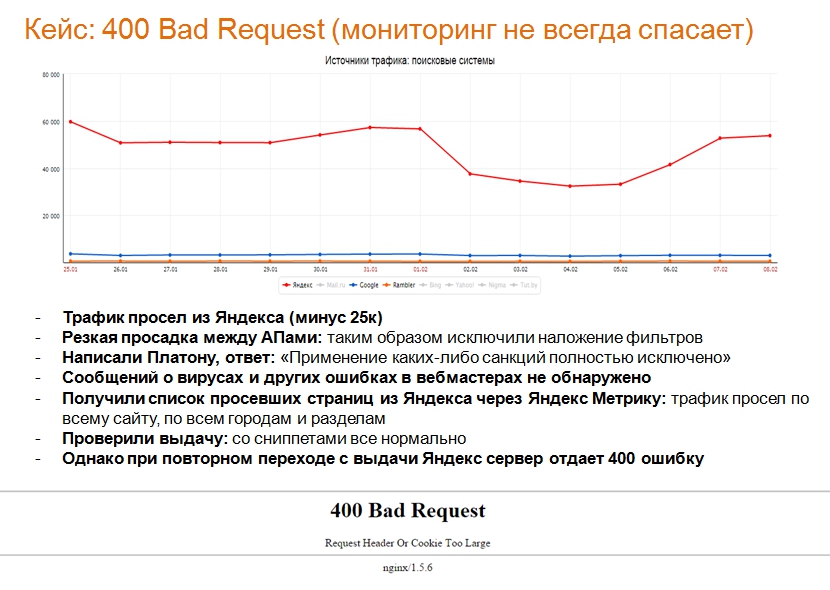
Нестандартна ситуація – сайт доступний, трафік в Яндексі падає. Наш невеликий кейс:
2. Чи можуть бути проблеми з редиректом – власники переносять сайт на новий движок і забувають налаштувати 301 редирект. Здавалося б, очевидно, але така помилка зустрічається часто.
Відстежити просто: Google Search Console – Помилки сканування – Помилки 404 (у вас різко зростатиме кількість 404 помилок):
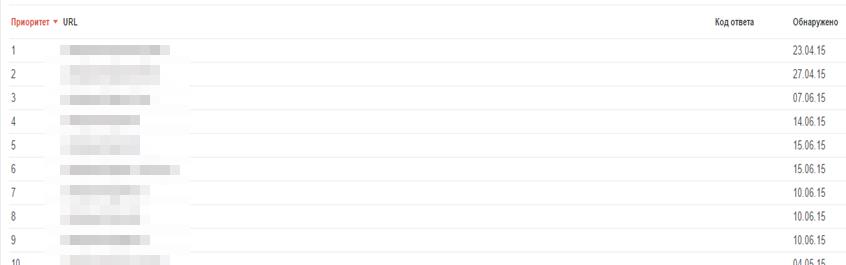
Повідомлення в Яндекс.Вебмайстер:

У нас був випадок – власник сайту вирішив переїхати на інший хостинг, в редирект просто поміняли головне дзеркало з www на без www. Трафік з Яндексу просів досить швидко. Вийшла така ситуація – сайт-головне дзеркало вилетів, перестав бути головним, на піддомені був тестовий сайт, його Яндекс проіндексував і зробив його головним дзеркалом.
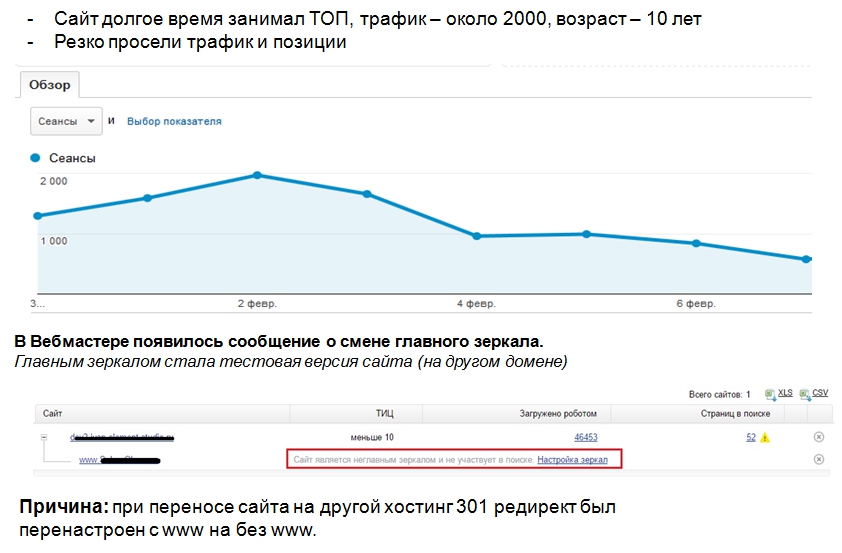
Завжди стежте за повідомленнями у вебмайстрах і 301 редирект.
3. Може просісти через віруси.
Також моніторимо повідомлення у Вебмайстрах:
– Яндекс:

– Google:
Можна перевірити в Google за посиланням https://goo.gl/4yMdJI.
Якщо віруси є, лікуватися можна за допомогою антивірусу Manul от Яндекса.
ІНШІ РЕКОМЕНДАЦІЇ:
- В robots.txt для кожного робота пишіть директиви окремо:
User-agent: Yandex
Disallow: /admin/
Host: site.ru
User-agent: Googlebot
Disallow: /admin/
- Формуйте sitemap.xml (бажано в автоматичному режимі)
- Код відповіді сторінки 404 не повинен бути 200, тільки 404 Not Found (це важливо)
- Підзаголовки (h1-h6) не беруть участь у верстці
- CSS і JS виносьте в окремі файли
- Сторінки пагінації не закривайте від індексації:
Єдині вимоги, які треба дотримуватися – для таких сторінок прописуємо унікальні title: Телевізори / Сторінка 2; Телевізори / Сторінка 3. Текст повинен індексуватися тільки на основній (першій) сторінці. Модифікуємо пагінатор, знижуємо рівень вкладеності:
Правильно (робот буде швидко переміщатися сторінками):
![]()
Неправильно:

КОРИСНІ ПОСИЛАННЯ:
Сервіси і програми:
SEOlib (відстеження позицій, оновлення алгоритмів і т.д.) – seolib.ru
Screaming Frog – https://screamingfrog.co.uk/seo-spider/
Google Search Console – https://www.google.ru/webmasters/
Яндекс.Вебмастер – https://webmaster.yandex.ru/sites/
Google Analytics – https://www.google.com/analytics/
Яндекс.Метрика – https://metrika.yandex.ru/
Google Page Speed – https://developers.google.com/speed/pagespeed/insights/
Web Page Test – https://www.webpagetest.org/
Яндекс Манул – https://yandex.ru/promo/manul
Почитать:
Блог SiteClinic – siteclinic.ru/blog
Докладна стаття про оптимізацію швидкості завантаження – https://habrahabr.ru/post/178561/
ПИТАННЯ НАШИХ СЛУХАЧІВ:
– Пагінація – це ж дублі?
Пагінація – це не дублі, картки товарів на сторінках пагінації різні, відповідно, і контент різний. Єдине – часто дублюється текст і тайтли, а це помилка, краще її не допускати.
– Чи вважається сторінка дубльованою, якщо я в тайтл додав артикул, видалив діскріпшін, але опис на сторінці залишився таким самим?
Якщо опис – це більша частина контенту, то так.
– Який текст тоді закривати на пагінації і як закривати?
Якщо у вас інтернет-магазин, лістинг товарів і внизу текст на 1000-1500 символів, цей текст на сторінках 2,3,4 потрібно закривати або видаляти. Для Яндексу можна закрити тегом no index або довантажувати його скриптами, закритими від індексації. Головне в robots.txt закрити від індексації скрипт, який виводить цей текст.
– А можна використовувати пагінації не в стандартному виконанні, а Аяксом довантажувати?
Можна, але в такому випадку бажано, щоб була html-версія цієї сторінки, щоб структура пагінації все одно зберігалася. Тобто користувач переходить як по сторінці пагінації, а пошуковику ми «віддаємо» html.
– Наскільки коректно прописувати сторінці canonical на саму себе? Поширена історія в вордпресі.
Обов’язково це треба робити, таким чином ми уникаємо появи великої кількості різних дублів.
– Як закривати від індексації за допомогою аякс? Я десь читав що скриптами закривати не можна, гугл вже бачить скрипти…
У нас виходу немає – є блоки, які нам потрібно закривати, так, робити це не можна, але якщо буде закритий один скриптик, я не думаю, що за це будуть застосовуватися якісь санкції.
– А навіщо пагінація в індексі?
У даному випадку нам важливо, щоб добре індексувалися картки товарів. Ми можемо прописати на сторінці пагінації метатег «noindex, follow», який закриє контент від індексації і залишить індексацію посилань, але не завжди це коректно працює. Тому для гарної індексації карток товарів, сторінки пагінації краще залишати в індексі.
– А як можна перевірити асинхронно завантажуються скрипти чи ні?
Анна Себова: Скрипт асинхронно завантажується, якщо:
1. Під час підключення скрипта вказано атрибут async або defer
2. Або в коді підключення вказано параметр async = true
Як, наприклад, у коді Google Analytics:
_gaq.push([‘_trackPageview’] );
(function() {
var ga = document.createElement(‘script’); ga.type = ‘text/javascript’; ga.async = true;
ga.src = (‘https:’ == document.location.protocol ? ‘https://ssl’ : ‘https://www’) + ‘.google-analytics.com/ga.js’;
var s = document.getElementsByTagName(‘script’)[0]; s.parentNode.insertBefore(ga, s);
})();
– Є кілька десятків тисяч подій, кожна подія – 1 сторінка. 90% подій минулі. Чи варто закривати ці сторінки, редирект робити або щось ще? Проблема в тому, що трафік з ПС йде на минулі події і це дратує людей.
Можна робити 301 редирект на сторінку категорії, до якої належить ця подія.
– Якщо робити 301 редирект з минулих подій, чи не просяде трафік у подальшому, по ідеї сторінки вилетять з індексу.
Сторінки вилетять з індексу, але ви можете прокачувати основні категорії. Ми так робимо на сторінках з нерухомості, наприклад, – з старих карток робимо 301 редирект.
– Наскільки важливою є перевірка на валідність html-коду?
Важлива, але не критична. Якщо у вас зовсім невалідний код, великий і з грубими помилками, то, напевно, за інших рівних умов це буде мінус в порівнянні з конкурентами. Але щоб це сильно впливало на рейтинг сайту, я не помічав. Звичайно, краще, щоб він працював добре.
– (robots.txt) – чи потрібно писати окремі директиви для мобільного робота гугла і яндекса?
Треба, зараз мобільним версіями приділяють багато уваги.
– У пошук для окремих товарів у видачу Яндексу потрапляє сторінка розділу, а не картки товарів.
Індивідуальне питання – може бути, у вас погано оптимізована картка товару, може, закрита від індексації, може, з’явилася недавно – варіантів може бути дуже багато – треба дивитися. Хочу сказати, що якщо релевантність періодично змінюється, це можуть бути і експерименти Яндексу.
– Який % різного змісту повинен бути на сторінці, щоб не вважати її дублем?
Наприклад, у медичній тематиці цілком припустимо 80% однакового контенту, в будівельній, скоріше, краще менше – відсотків 30-40. Якщо не знаєте відповідь, дивіться по топу. Якщо в ТОПі багато сторінок з такими дублями, то, швидше за все, це допустимо,
– Як відстежувати дублі?
Щоб відстежувати і контролювати ситуацію, раджу раз на місяць проводити міні-аудит сторінок через Screaming Frog, дивитися на Search Console,
– Трафік з Яндексу в 2 р. менше, ніж трафік з Google.
Це поширена ситуація, частки трафіку різні, іноді ранжування відрізняється, наприклад, Google реагує на якийсь невеликий Переп’є, регіональність у нього зовсім інша, комерційні він визначає по-іншому. Так що це нормальна ситуація.
Якщо у вас є якісь питання, обов’язково задавайте їх у коментарях!
Еще по теме:
- Запис вебінару «Як створити ефективне семантичне ядро»
- Юзабіліті на практиці – покращуємо конверсію, позиції та трафік (відео з вебінару)
- Запис і текст вебінару: Як проаналізувати сайти конкурентів

Оцените мою статью:
 (6 оценок, среднее: 5,00 из 5)
(6 оценок, среднее: 5,00 из 5)
Есть вопросы?
Задайте их прямо сейчас, и мы ответим в течение 8 рабочих часов.